PSTAT 5A: Lecture 02
Descriptive Statistics, Part II
2023-04-06
- Notice that each observational unit of this data matrix (consisting only of the
bill_length_mmandbill_depth_mmvariables) is a pair of numbers.
- It is fairly natural, then, to imagine plotting these pair of numbers on a Cartesian coordinate system.
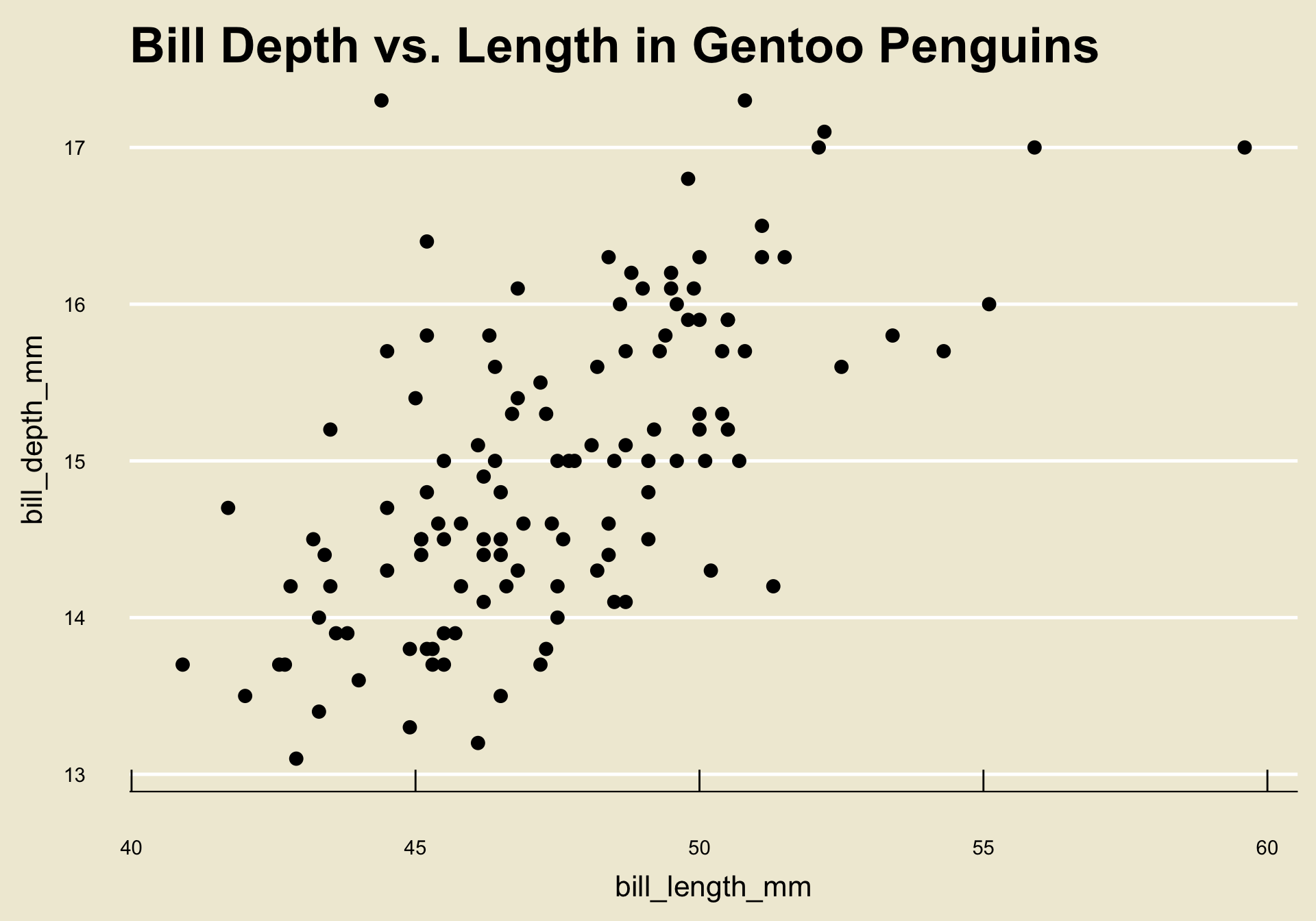
Interpreting Scatterplots
- Let’s return to the scatterplot we generated before:
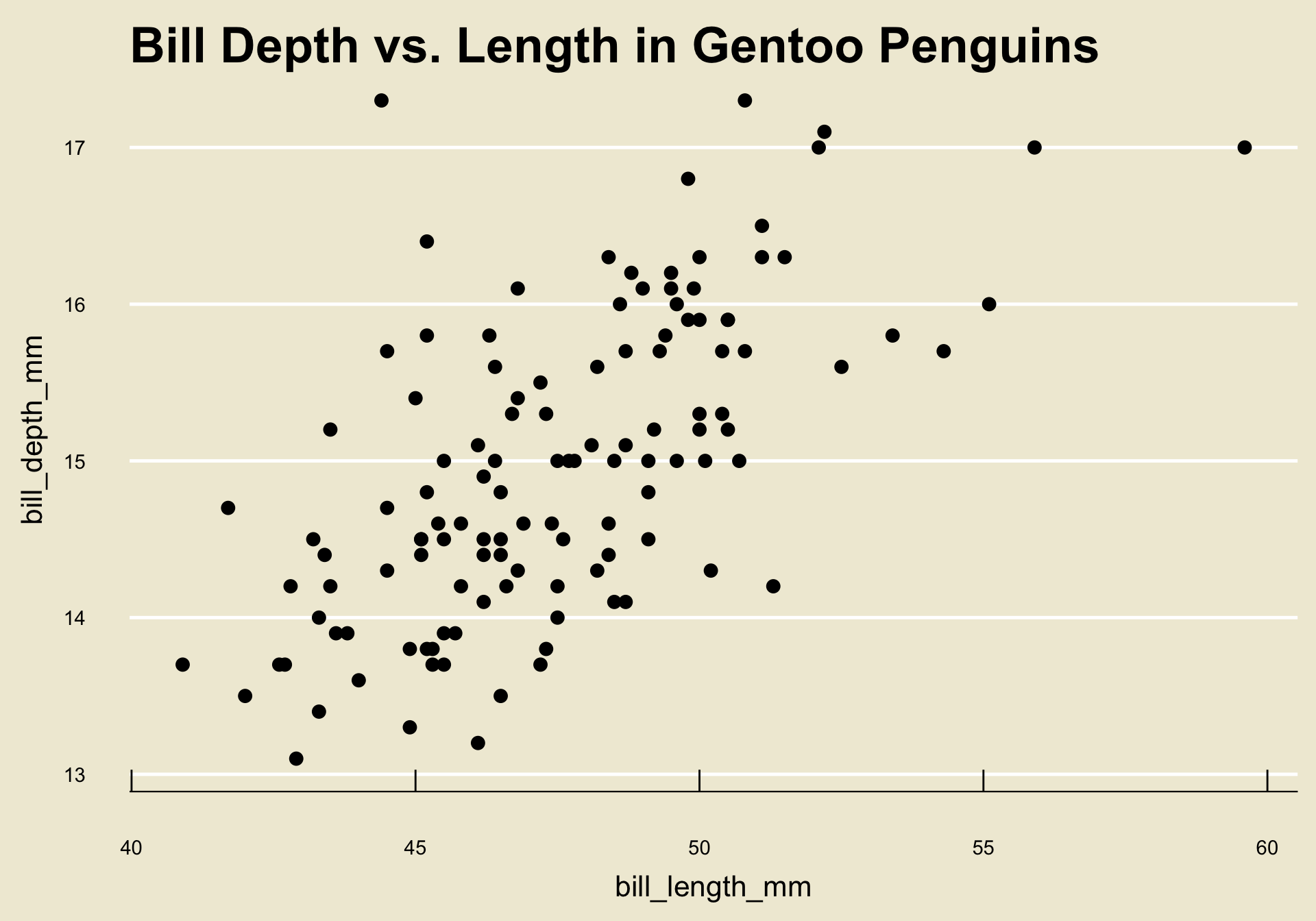
Notice how as the values of
bill_length_mmincrease, the corresponding values ofbill_depth_mmalso increase on average?- This makes intutive sense: longer bills are probably deeper!
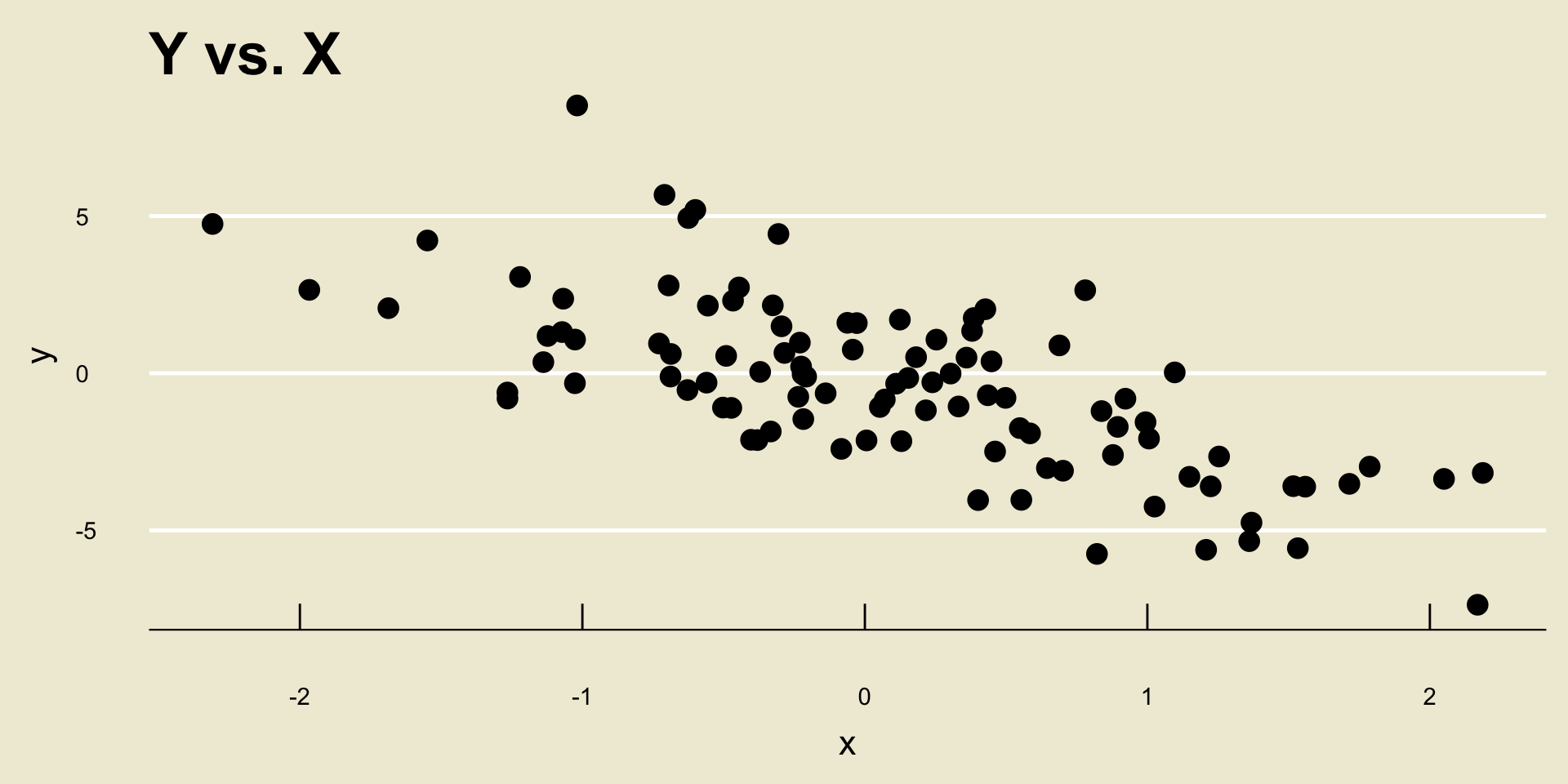
- Linear Negative Trend:
- Nonlinear Negative Trend:
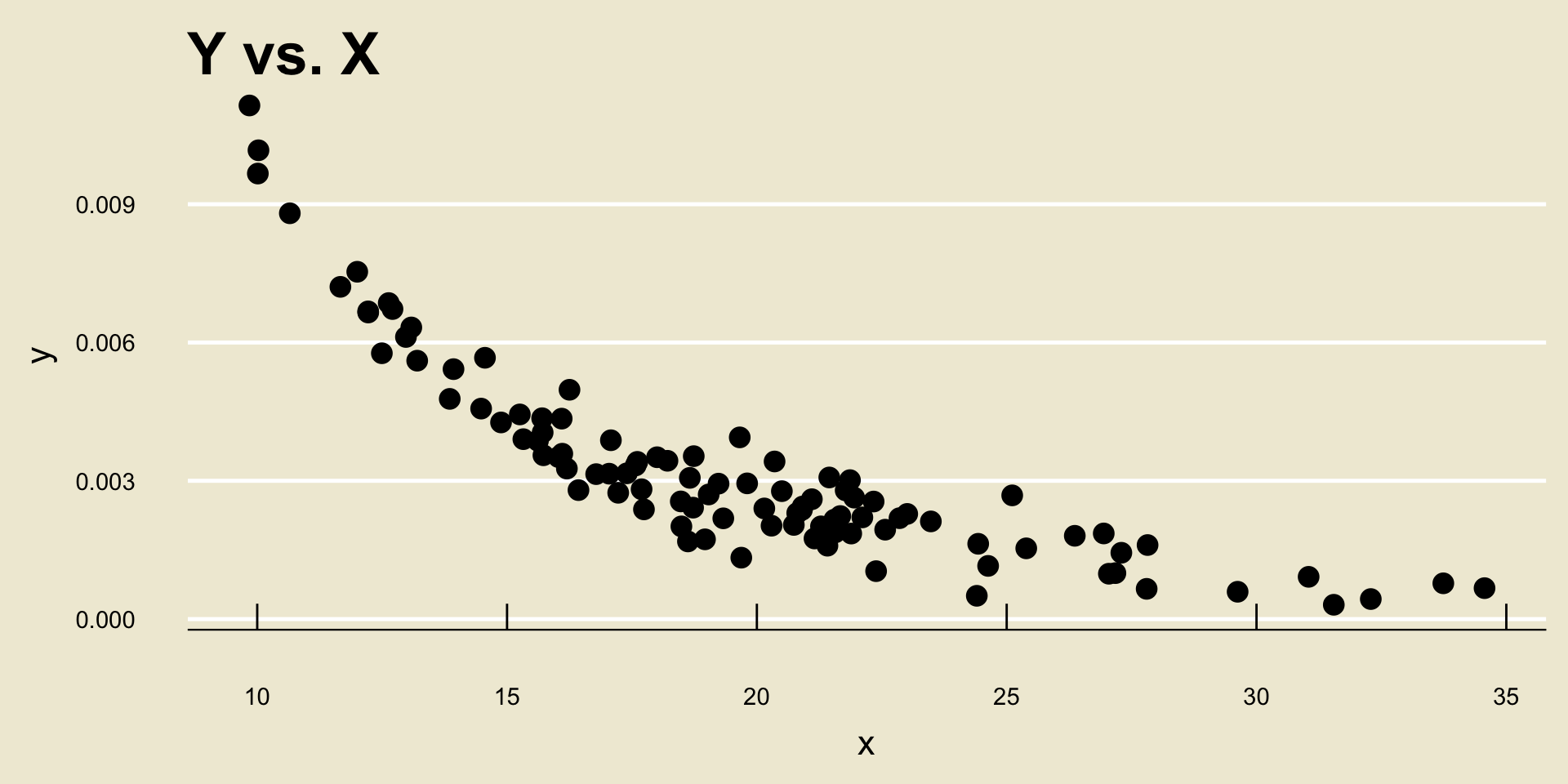
- Nonlinear Positive Trend:
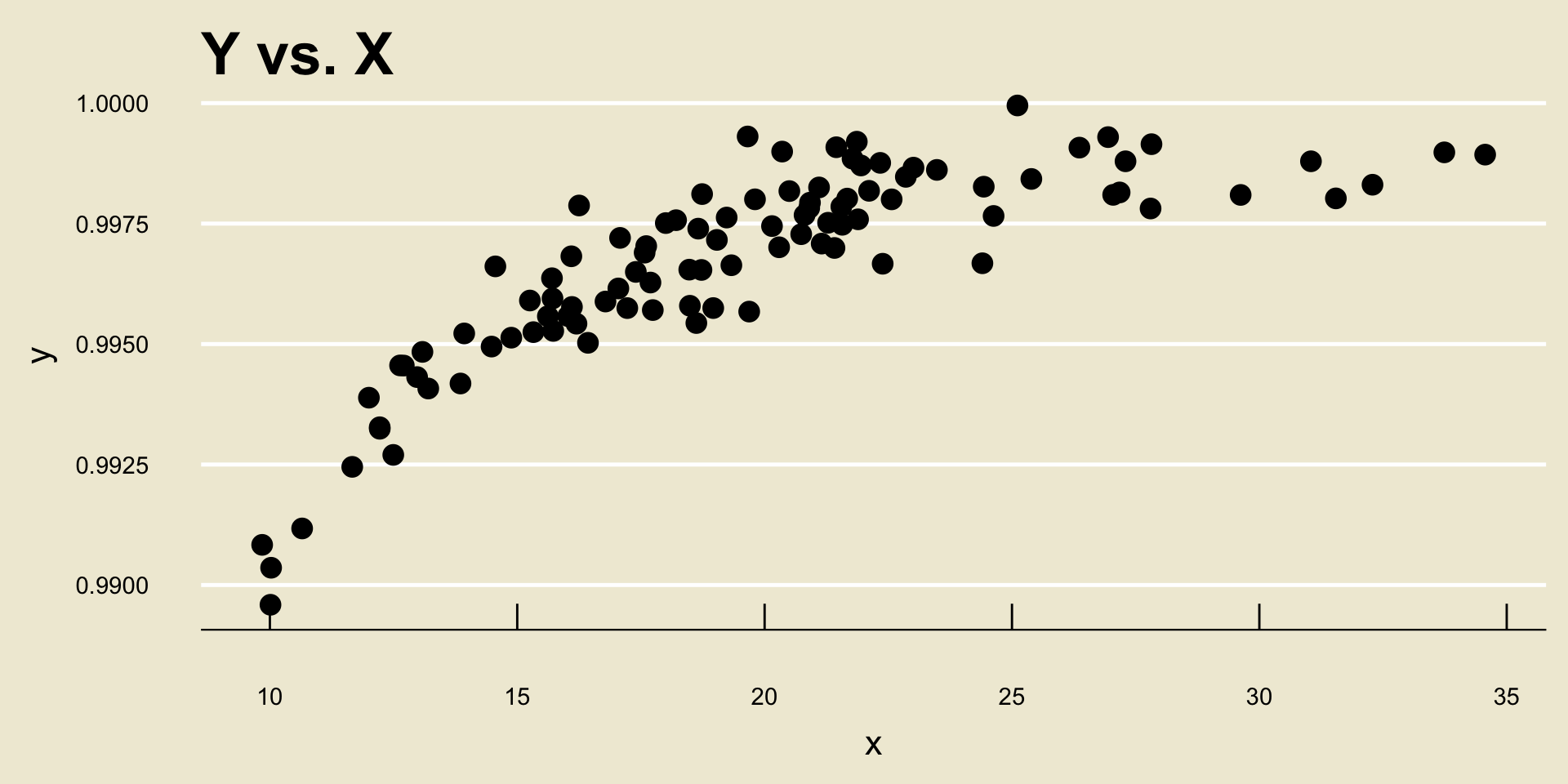
- No Discernable Trend
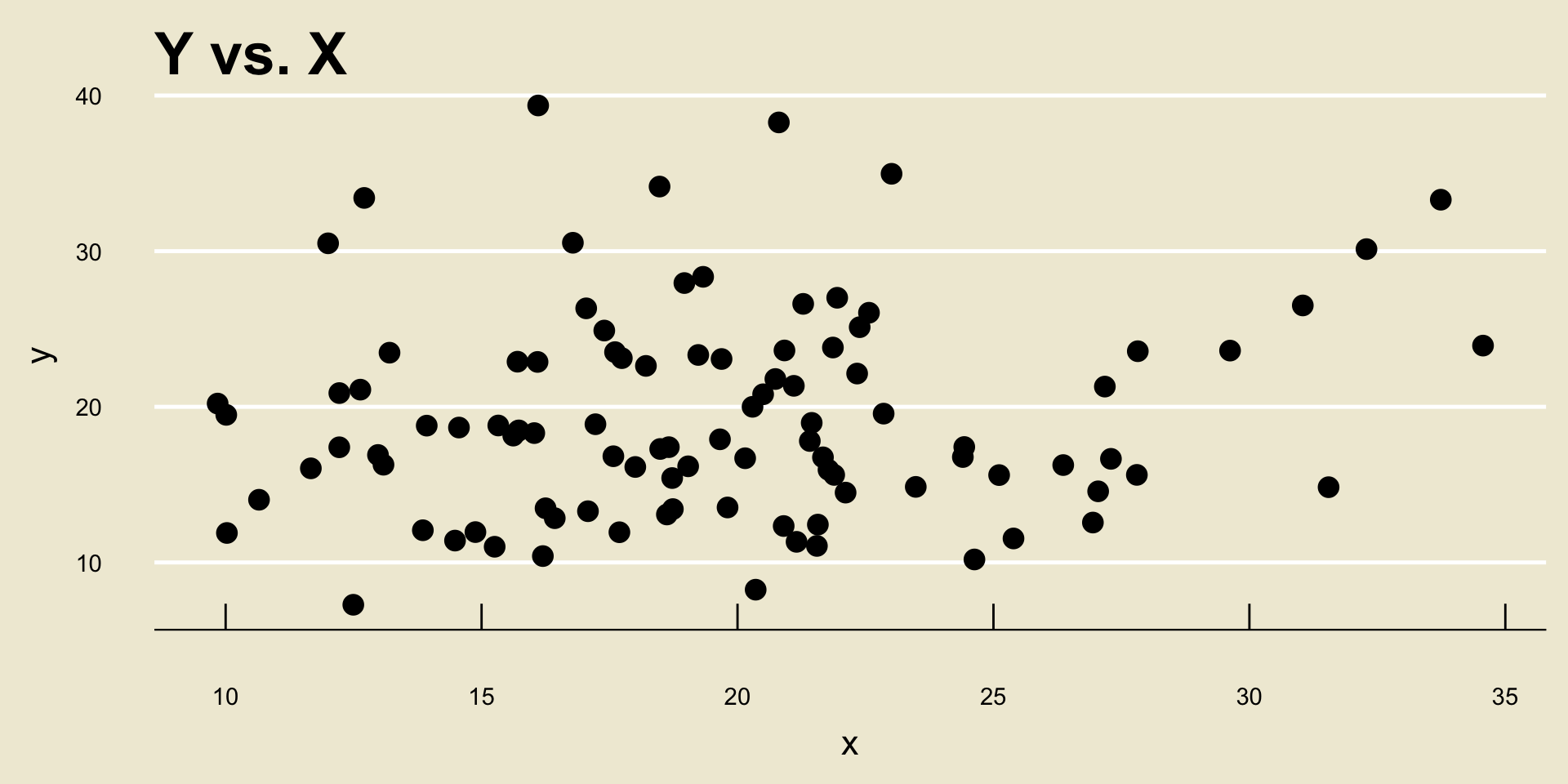
- The way we get around this is, perhaps surprisingly… boxplots!
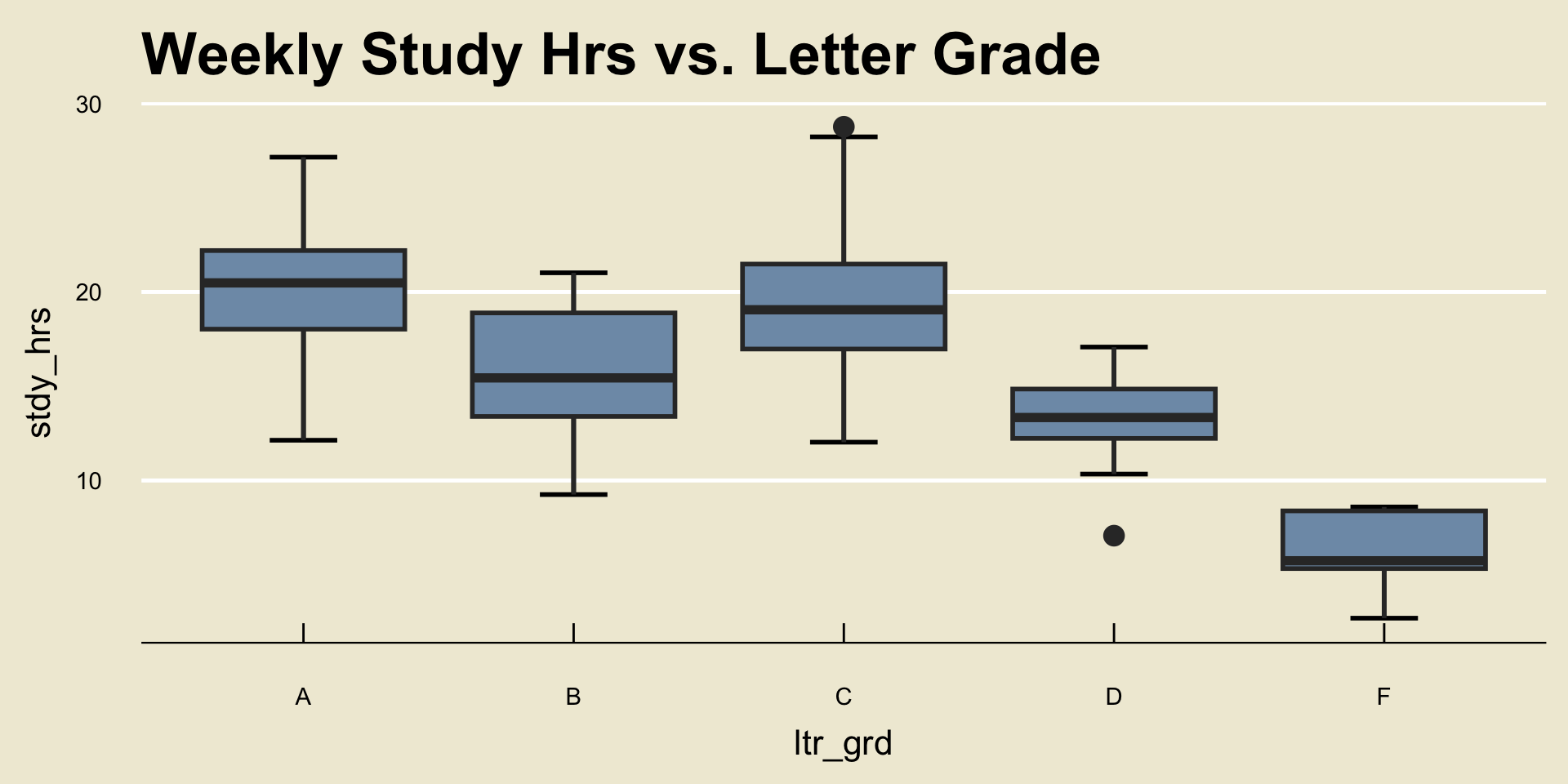
- This type of plot is called a side-by-side boxplot
Quantifying “Center”
Here is a very broad question: what is the center of a dataset \(X = \{x_i\}_{i=1}^{n}\)?
Perhaps the scores dataset from earlier is a bit too complicated- let’s simplify things and look at the dataset \[ X = \{1, 1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 6\} \]
As a starting point, I can “plot” these points on a number line (to produce what is known as a dotplot):

Quantifying “Center”
- Back to our question: what is the center of this dataset?
- Perhaps we can think of center as a balancing point. In other words: where should I place a fulcrum to ensure this number line remains balanced?

- We call this balancing point the arithmetic mean (or just mean, or average, for short), and denote it \(\overline{x}\).
- This notion of a “balancing point” applies to any set of numbers! For example, the dotplot of the exam scores dataset from before looks like:

Leadup
Now, there is another way to think about spread: suppose we look at the average distance of points from their mean.
More specifically: define \(d_i := x_i - \overline{x}\) to be the deviation of the \(i\)th point from the mean:

Time for an Exercise!
Exercise 4
Consider a dataset \(X\) that has boxplot given by:
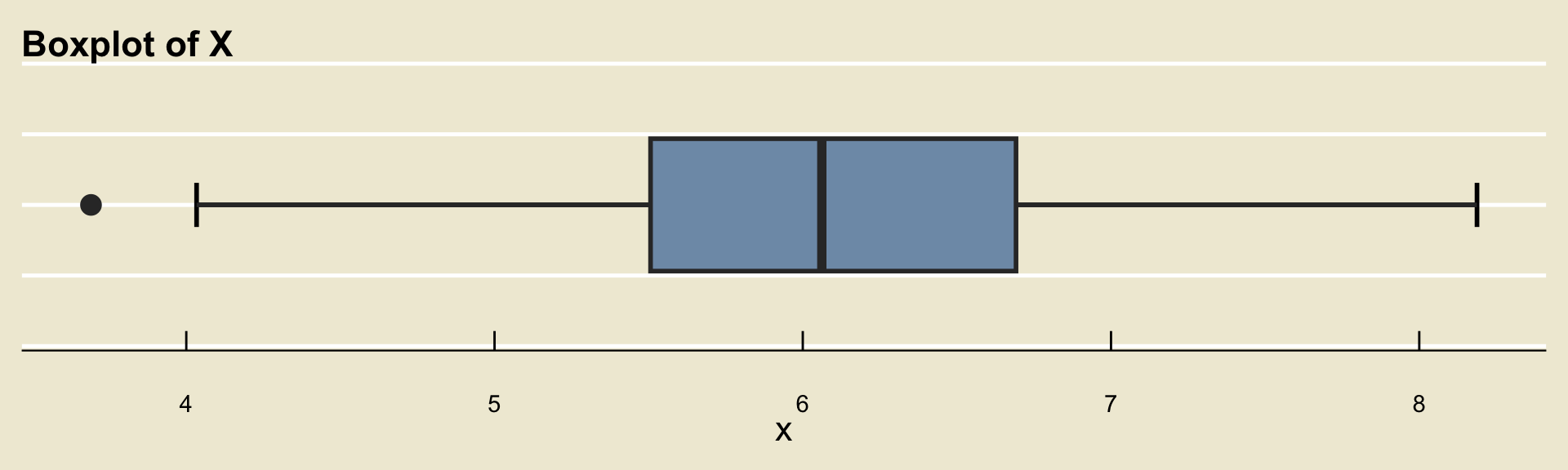
Provide the five number summary, along with the IQR. Discuss with your Neighbors!
Summary
We started off by finishing our discussion of data visualizing, identifying ways to visualize the relationship between two variables.
Such visualizations included: scatterplots and side-by-side boxplots.
We also discussed notions of trend.
Next, we discussed various numerical summaries of data.
These included measures of central tendency (like the mean or the median), along with measures of spread (like the variance, standard deviation, or IQR).
We were also introduced to the five number summary, which is closely related to boxplots.
Next time we’ll begin our discussion on Probability, which, as we will see, provides a rigorous way of quantifying uncertainty.
