PSTAT 5A: Lecture 09
Continuous Random Variables
2023-05-02
- …then the probability \(\mathbb{P}(0.25 \leq X \leq 0.75)\) is represented by the following area:


- Note that the area under this density curve is (using the formula for the area of a rectangle) \[ (b - a) \times \left( \frac{1}{b - a} \right) = 1 \] as we expected!
Uniform Density Curves
- Oftentimes, we will be a bit lazy with our density curve and omit the open/closed circles. For example, we might sketch the density curve of the \(\mathrm{Unif}(1, \ 2.15)\) distribution as
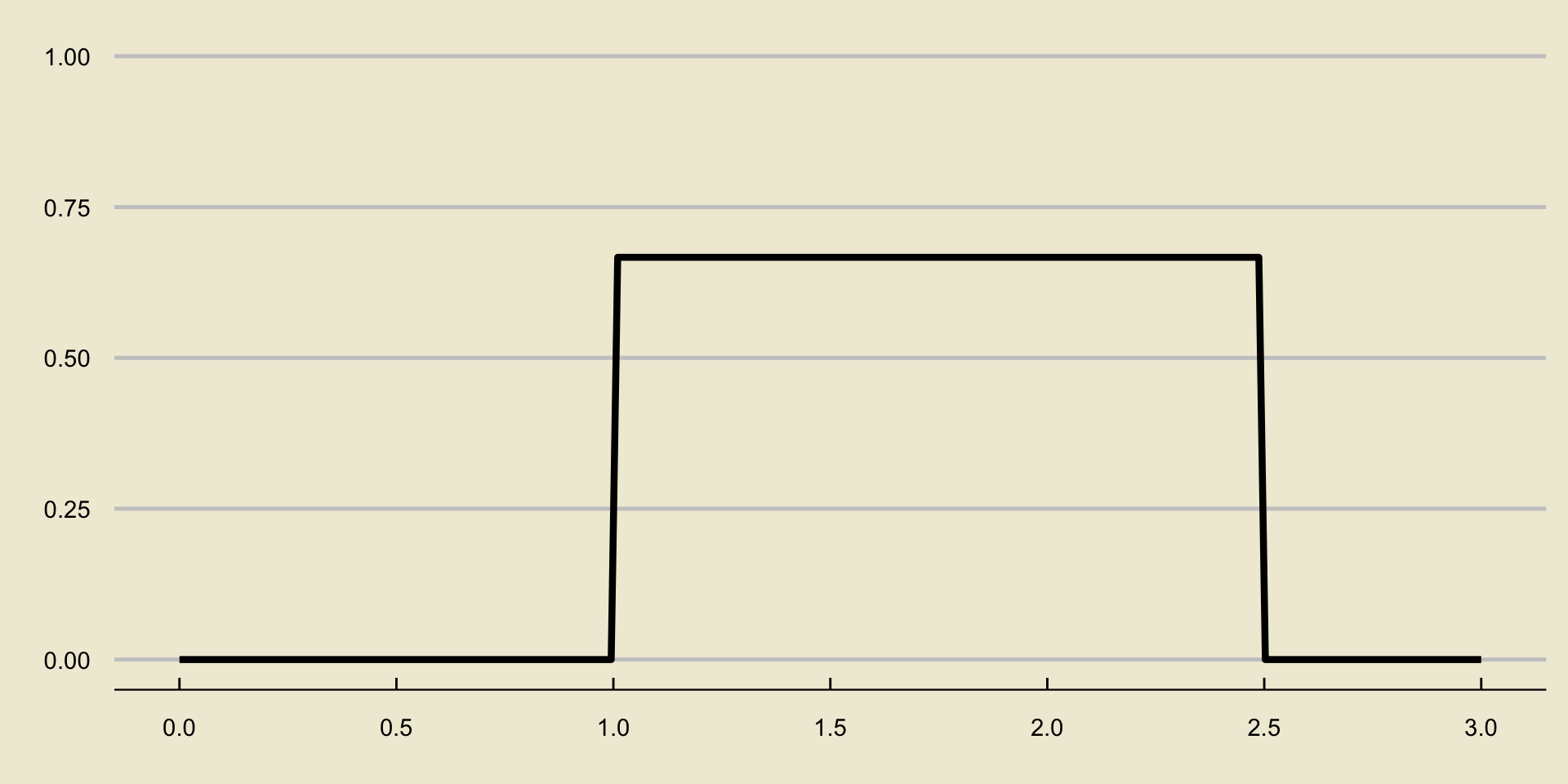
Solution
- When working through probability problems involving continuous distributions, sketching a picture is always a good first step.
- Sometimes, we will explicitly make that the first step of a problem, meaning failure to sketch a relevant picture may result in less-than-full marks!
- The density curve of the \(\mathrm{Unif}(-1, \ 1)\) distribution is given by
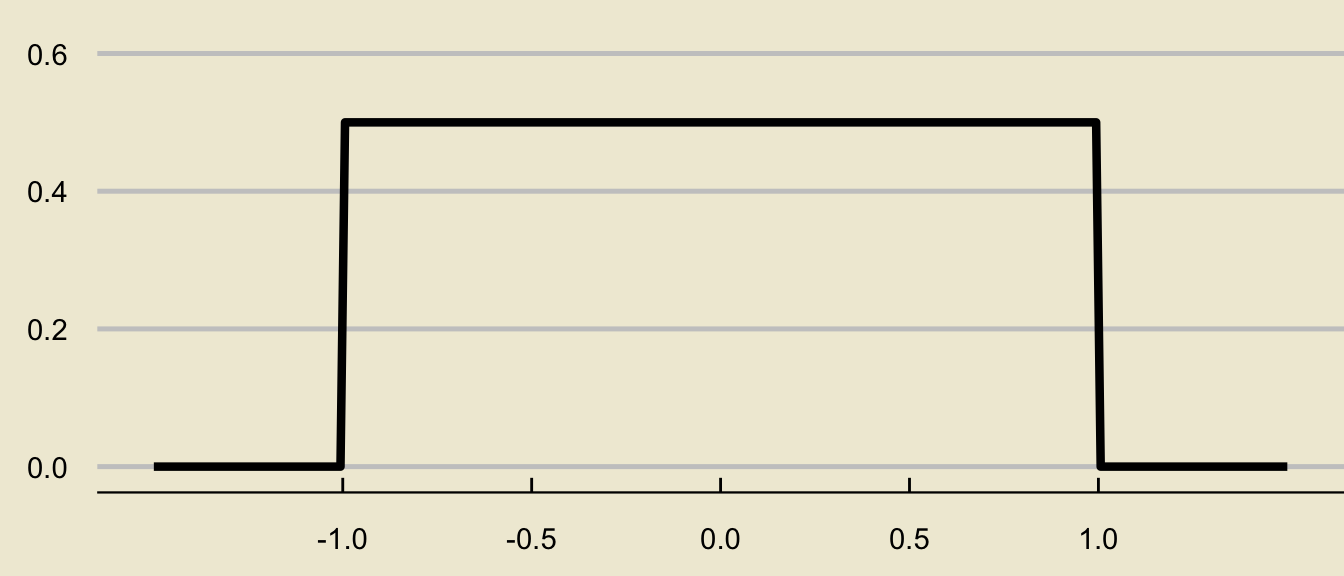
Solution
- The desired probability is thus
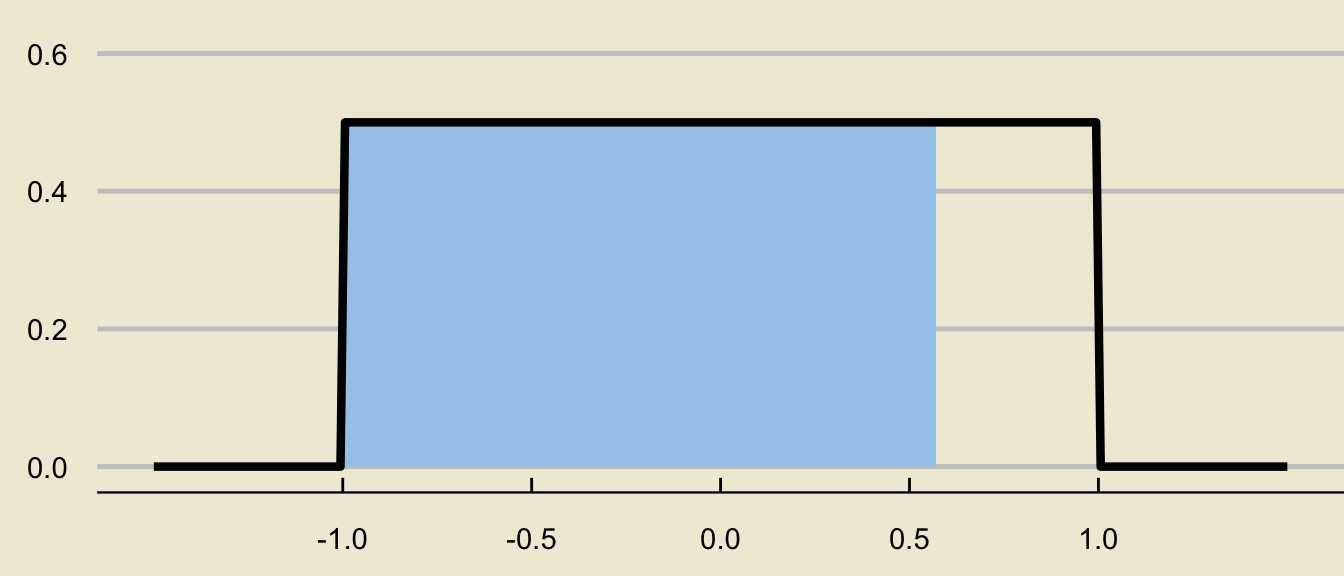
- This is a rectangle with base \((0.57 - (-1)) = 1.57\) and height \(1 / (1 - (-1)) = 1/2\). Therefore, the area of this rectangle - and, also, the desired probability - is \[ (1.57) \times \frac{1}{2} = \boxed{0.785 = 78.5\%} \]
Another Example
Worked-Out Example 2
If \(X \sim \mathrm{Unif}(0, 1)\), compute \(\mathbb{P}(0.25 \leq X \leq 0.75)\).
- We are going to solve this problem in two different ways.
- Again, we always begin with a sketch of the desired probability as an area underneath the density curve:
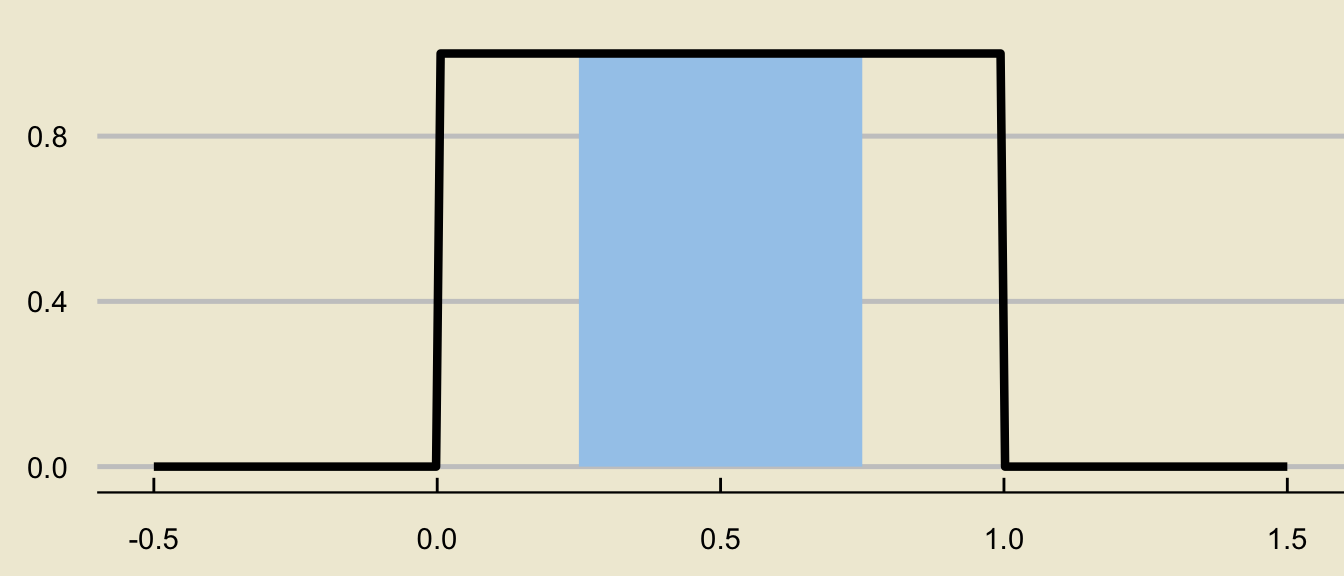
- This is a rectangle with base \((0.75 - 0.25) = 0.5\) and height \(1 / (1 - 0) = 1\), meaning its area is \[ (0.5) \cdot \left(1 \right) = \boxed{0.5 = 50\%} \]
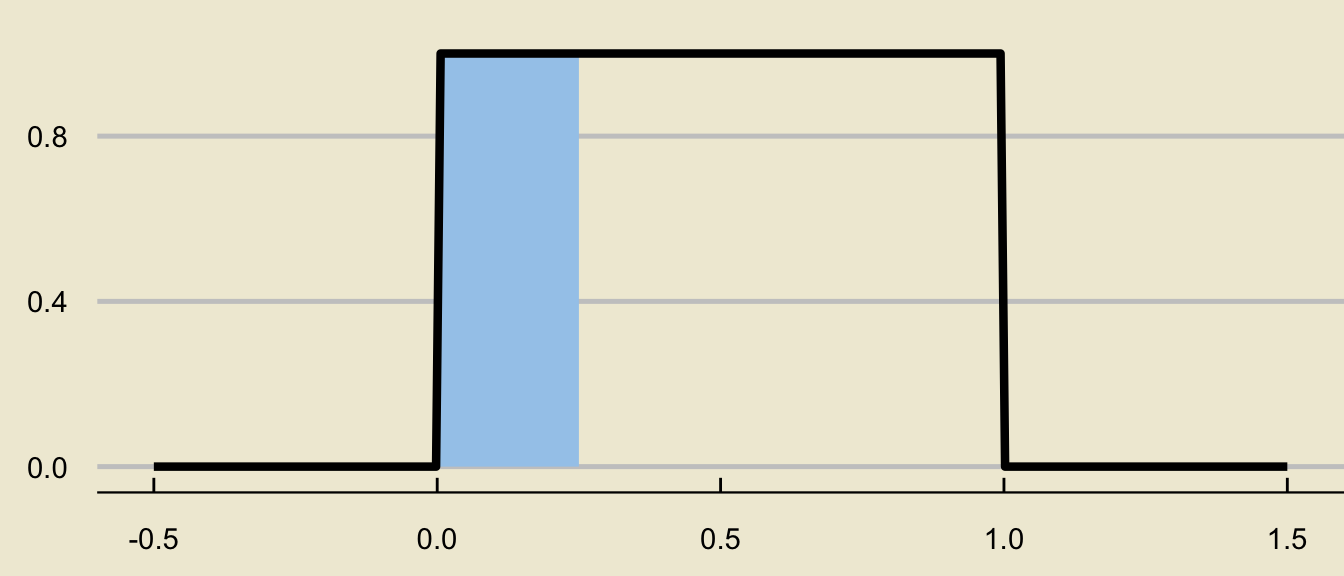
- Another way we can think about this area, however, is as a difference of two areas:
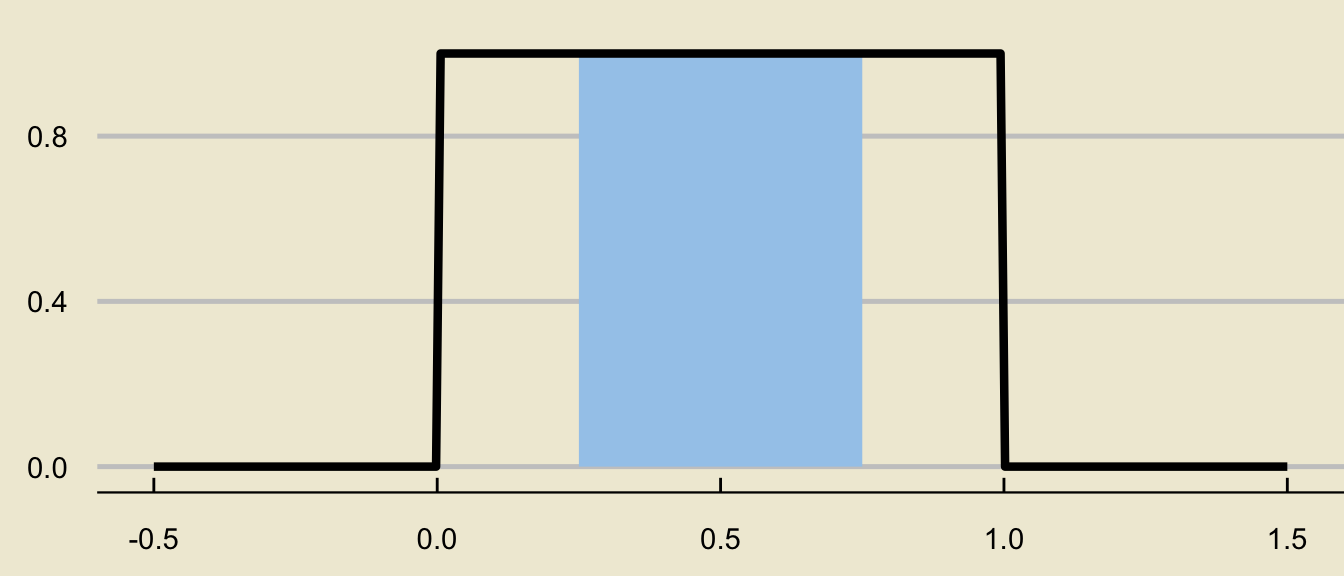
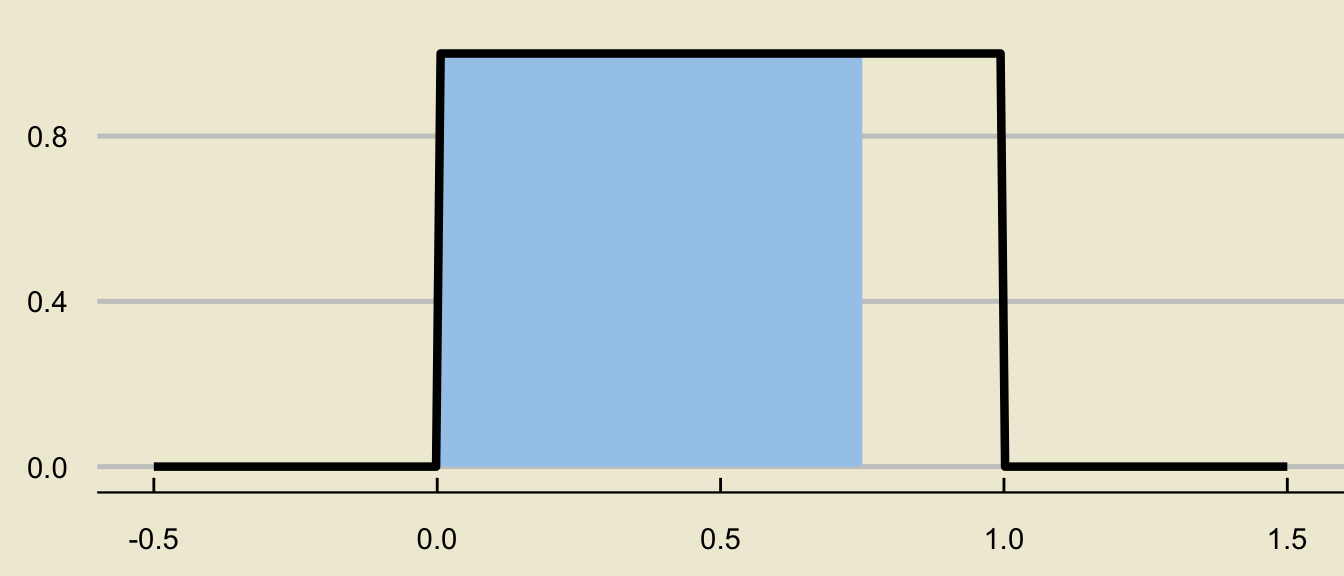
\[ \huge - \]
Tail Probabilities
- This is not a coincidence!
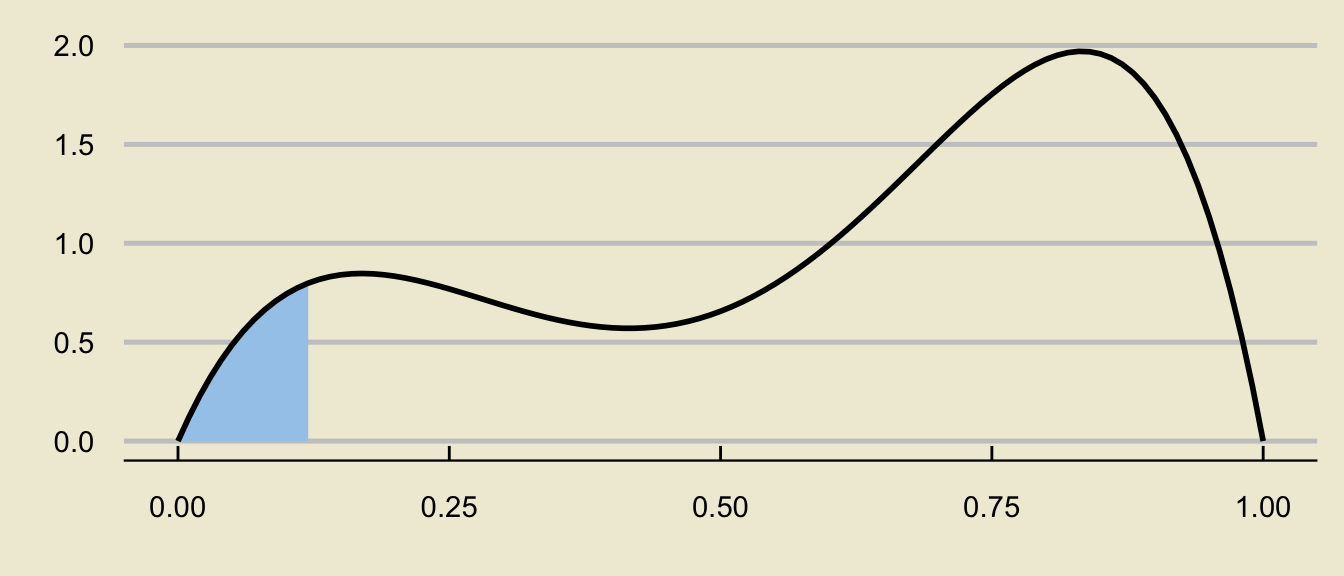
- For a more arbitrary distribution:
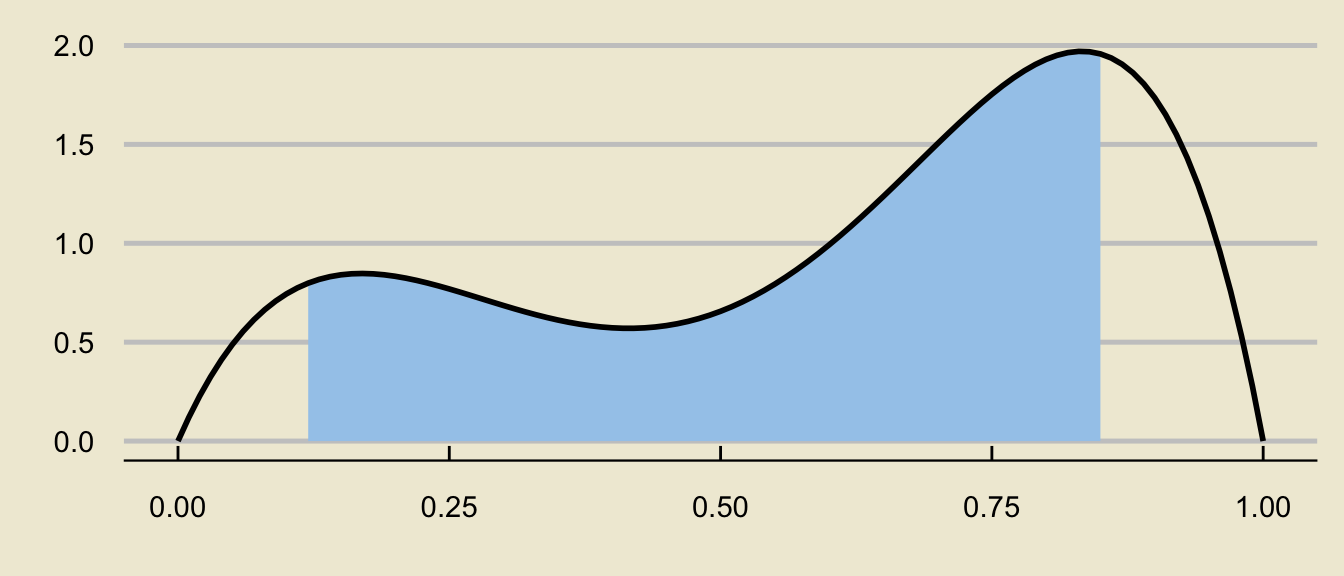
can be decomposed as
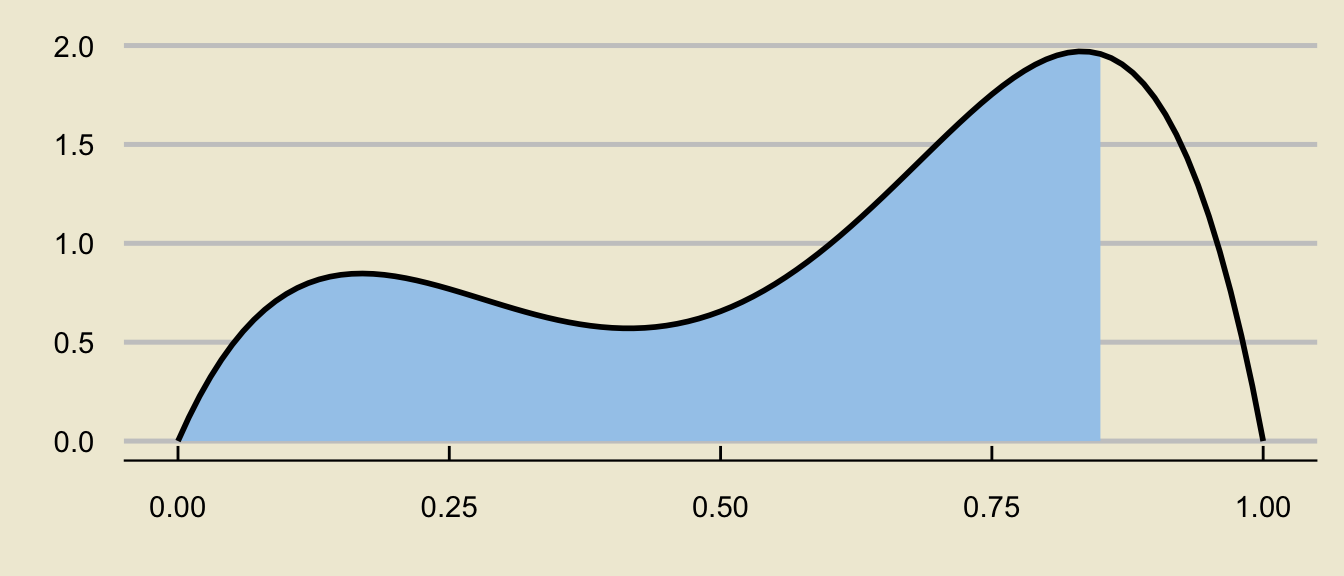
\[ \huge - \]
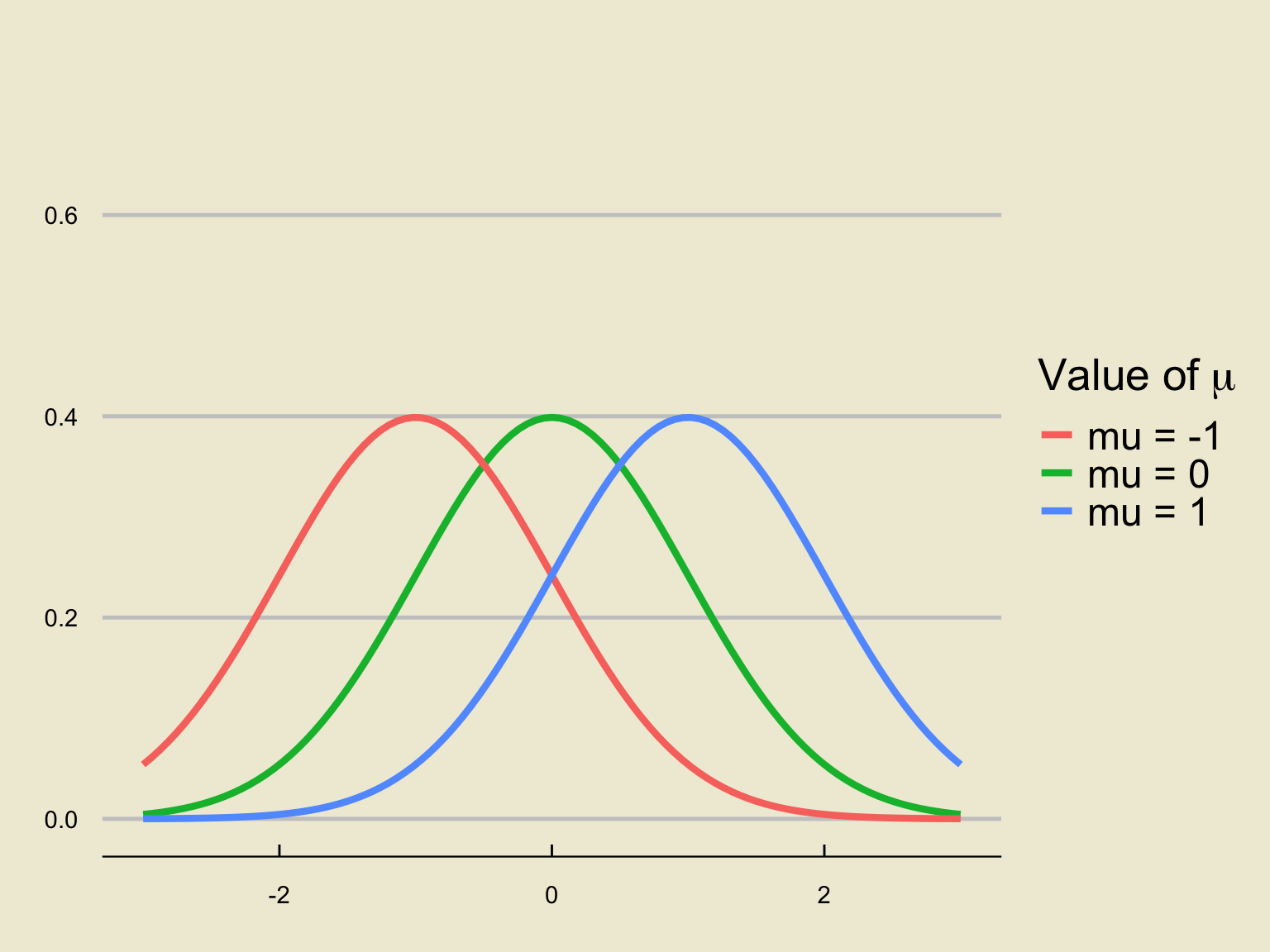
Changing \(\mu\)
Holding \(\sigma = 1\) fixed and varying \(\mu\), we find:
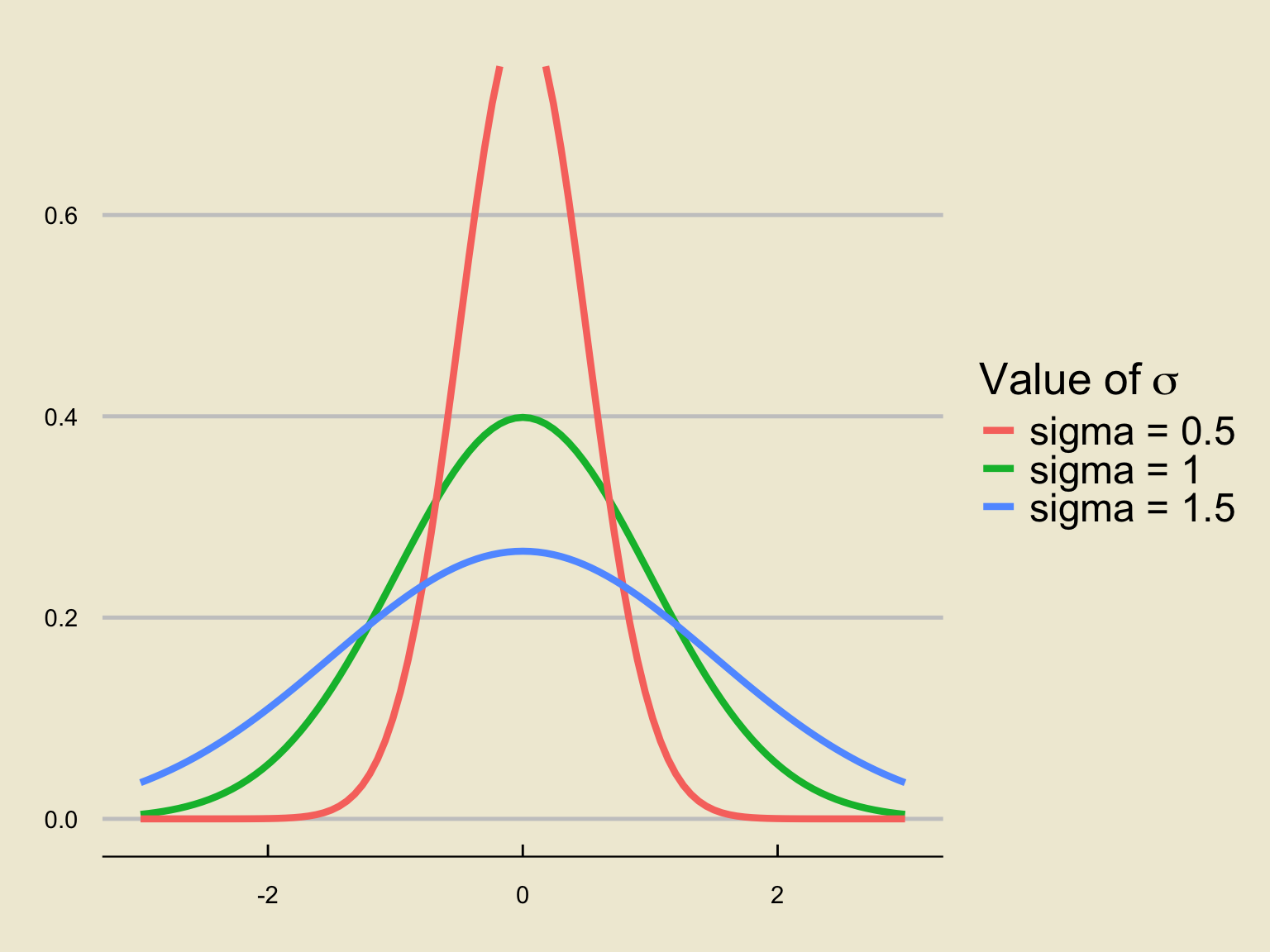
Changing \(\sigma\)
Holding \(\mu = 0\) fixed and varying \(\sigma\), we find:
Standard Normal Distribution
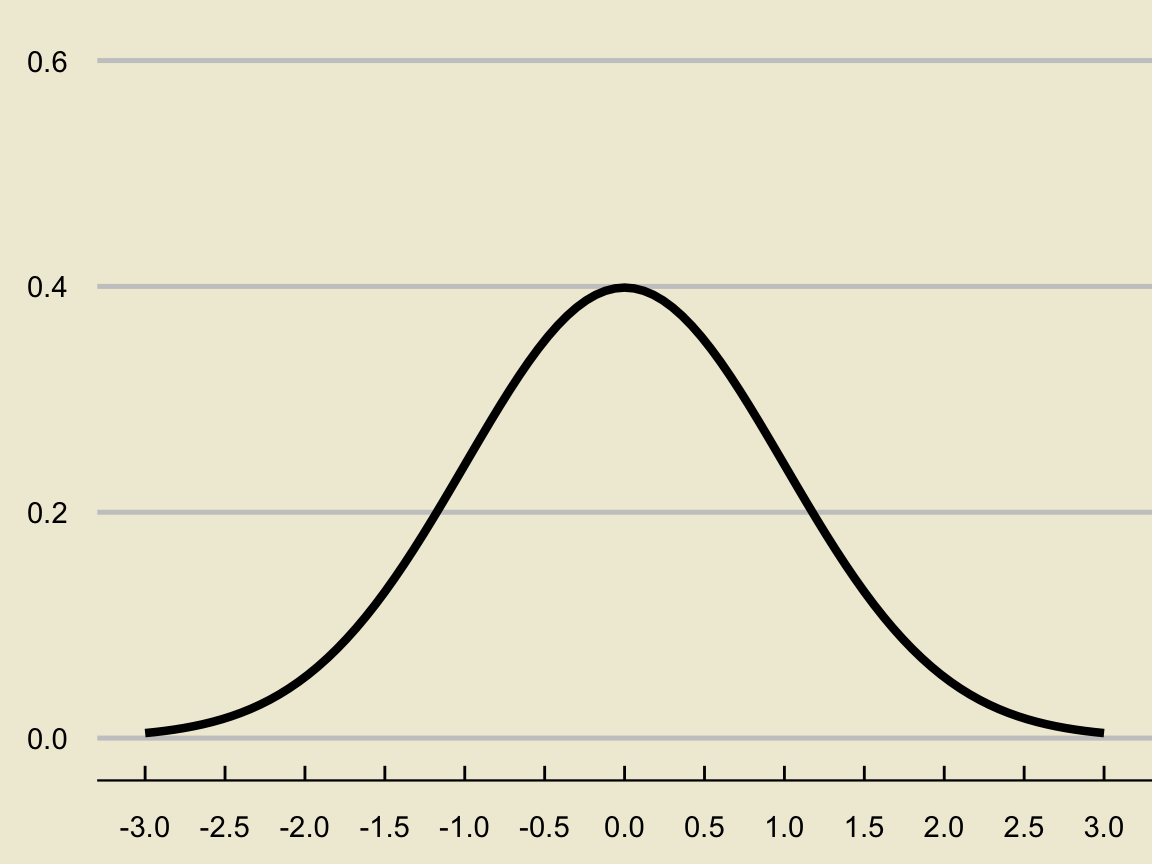
Definition
The standard normal distribution is the normal distribution with \(\mu = 0\) and \(\sigma = 1\); i.e. \(\mathcal{N}(0, 1)\).
Normal Probabilities
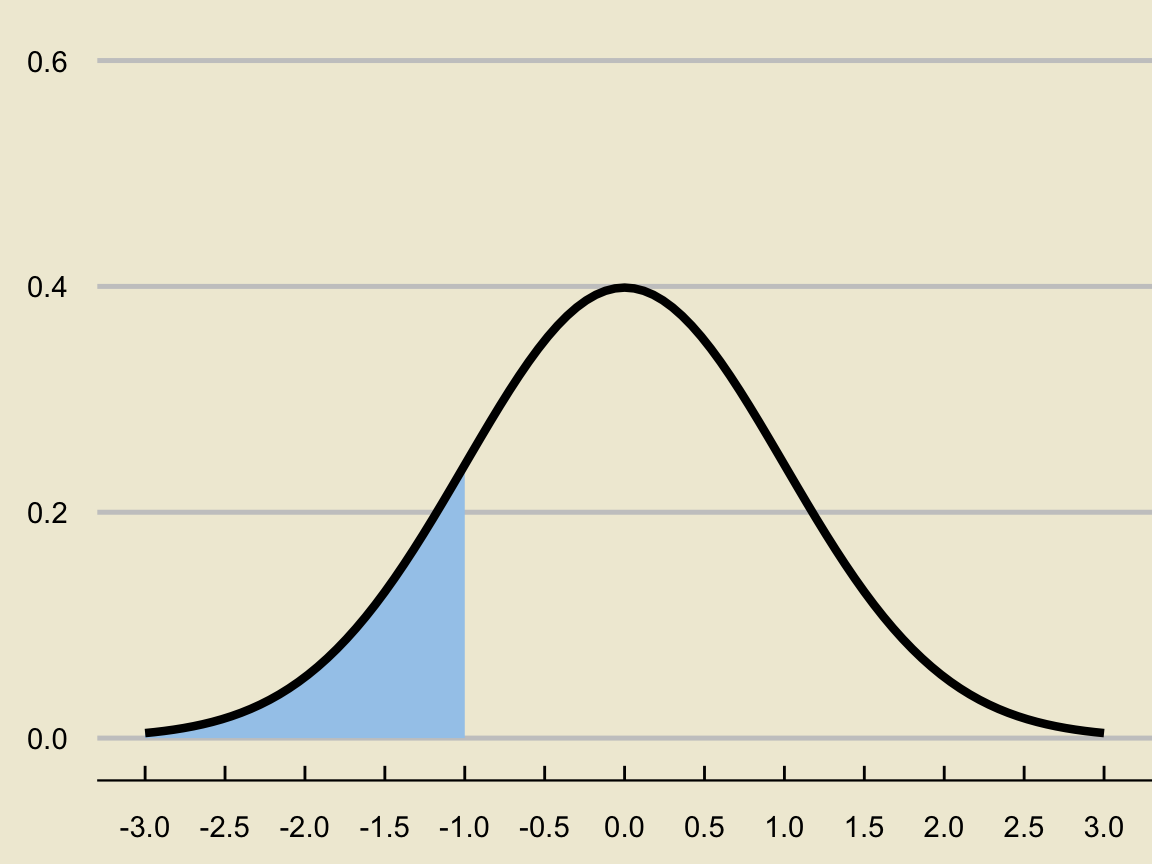
- Recall that for continuous variables, probabilities are found as areas underneath the density curve. For example, if \(X \sim \mathcal{N}(0, 1)\), then \(\mathbb{P}(X \leq -1)\) is found by computing the area below:
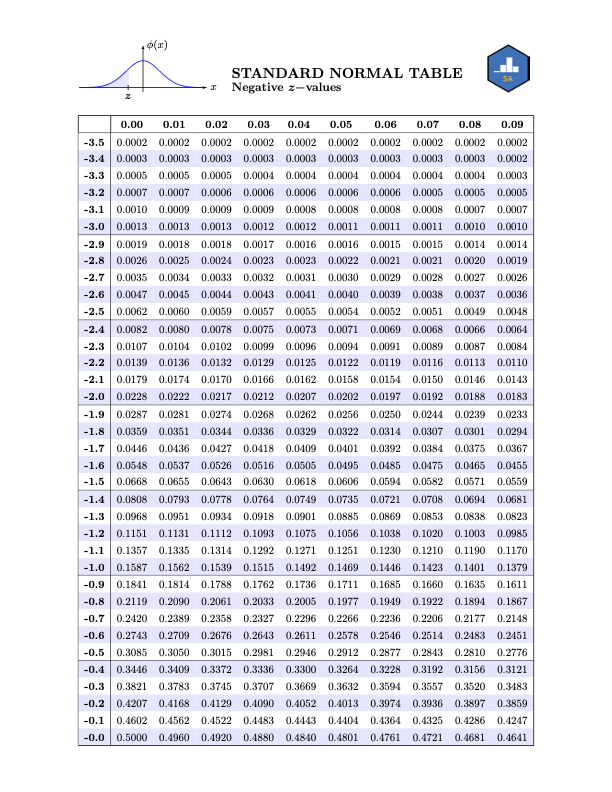
Normal Table
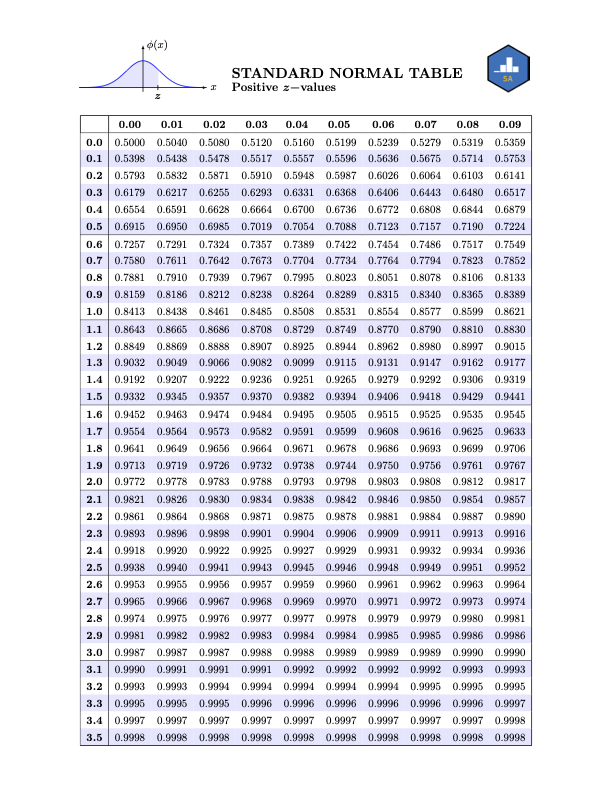
Reading the Normal Table
- To find \(\mathbb{P}(Z \leq 0.83)\), we break up \(0.83\) as \[ 0.83 = 0.8 + 0.03 \]
- This tells us to find the desired probability in the intersection of the \(0.8\) row and the \(0.03\) column:

Another Example
Worked-Out Example 4
If \(Z \sim \mathcal{N}(0, 1)\), find
- \(\mathbb{P}(Z \leq -1.01)\)
- \(\mathbb{P}(Z \leq -2.25)\)
- \(\mathbb{P}(-2.25 \leq Z \leq -1.01)\)
- \(\mathbb{P}(X \geq -0.7)\)
Mean and Variance of the Normal Distribution
If \(X \sim \mathcal{N}(\mu, \ \sigma)\), we have the following results:
- \(\displaystyle \mathbb{E}[X] = \mu\)
- \(\displaystyle \mathrm{Var}(X) = \sigma^2\)
So, the two parameters we use to describe the normal distribution are the mean and the variance.
We’ll talk more about parameters in the next lecture.
