PSTAT 5A: Lecture 12
Inference on the Mean
Ethan P. Marzban
2023-05-11
Previously
Over the course of the past few lectures, we’ve been dealing primarily with population proportions.
A natural point estimate of \(p\) is \(\widehat{P}\), the sample proportion, and used the Central Limit Theorem to figure out what its sampling distribution is.
We then used the sampling distribution of \(\widehat{P}\) to construct confidence intervals for the true proportion \(p\).
Now we will turn our attention to a different population parameter.
Leadup
- Recall from last lecture that any of the descriptive statistics we discussed in Week 1 can be viewed as population parameters, when they apply to the population.
- E.g. population proportion (\(p\)), population variance (\(\sigma^2\)), etc.
- Of particular interest to statisticians is often the population mean, \(\mu\).
- Let’s try and draw some analogies from our work with population proportions.
- When trying to make inferences on a population proportion \(p\), we used the sample proportion \(\widehat{P}\) as a proxy (specifically, a point estimator).
- Any guesses on what we might use as a point estimator of \(\mu\)?
- That’s right- the sample mean \(\overline{X}\)!
Notation
Again, it will be useful to establish some notation:
- \(\mu\) represents the population mean, and is deterministic (i.e. fixed) but unknown.
- \(\overline{X}\) represents the mean of some hypothetical sample, and is therefore random (as different samples result in different sample means)
- \(\overline{x}\) represents the mean of a specific sample, and is therefore deterministic (i.e. “we’ve taken this particular sample right here and computed its mean).
Just as \(\widehat{P}\) has a sampling distribution, so too does \(\overline{X}\).
The sampling distribution of \(\overline{X}\), however, will end up requiring a bit more work.
General Confidence Intervals
We will follow the general idea we used before of constructing confidence intervals as \(\widehat{\theta} \pm \mathrm{m.e.}\).
In this case, we use \(\overline{X}\) as our point estimator.
It turns out that, assuming the population mean is \(\mu\) and the population standard deviation is \(\sigma\), and if \(\overline{X}\) denotes the mean of a sample of size \(n\), we have that \[ \mathrm{SD}(\overline{X}) = \frac{\sigma}{\sqrt{n}} \]
Therefore, our confidence intervals will take the form \[ \overline{X} \pm c \cdot \frac{\sigma}{\sqrt{n}} \] where the constant \(c\) depends on both the sampling distribution of \(\overline{X}\) as well as the confidence level.
Normal Population
Let’s work on finding the sampling distribution of \(\overline{X}\).
It turns out that the first thing we need to ask is whether the underlying population is normally distributed or not.
If the underlying population is normally distributed [again with population mean \(\mu\) and population standard deviation \(\sigma\)], we have that \[ \frac{\overline{X} - \mu}{\sigma / \sqrt{n}} \sim \mathcal{N}(0, \ 1) \] meaning the constant \(c\) should be selected as the appropriate percentile of the standard normal distribution: \[ \overline{x} \pm z_\alpha \cdot \frac{\sigma}{\sqrt{n}} \]
Worked-Out Example
Worked-Out Example 1
The heights of adult males is assumed to follow a normal distribution with mean 70 in and standard deviation 15 in. A representative sample of 120 adult males is taken, and the average height of males in this sample is recorded.
- What is the random variable of interest?
- Is the value of 70 in a population parameter or a sample statistic?
- What is the probability that the average height of males in the sample is between 69.5 in and 71.5 in?
Solutions
\(\overline{X} =\) the average height of a sample of 120 adult males.
The value of 70 in is a population parameter, as it is the true average height of all adult males.
The quantity we seek is \(\mathbb{P}(69.5 \leq \overline{X} \leq 71.5)\). Because the population is normally distributed, we can use our result above to conclude \[ \overline{X} \sim \mathcal{N}\left( 70, \ \frac{15}{\sqrt{120}} \right) \sim \mathcal{N}\left( 70, \ 1.369 \right) \]
- To find \(\mathbb{P}(69.5 \leq \overline{X} \leq 71.5)\), we therefore utilize the same techniques we used previously, when dealing with normal distribution problems: \[\mathbb{P}(69.5 \leq \overline{X} \leq 71.5) = \mathbb{P}(\overline{X} \leq 71.5) - \mathbb{P}(\overline{X} \leq 69.5) \]
Solutions
- The associated \(z-\)scores are \[\begin{align*} z_1 & = \frac{71.5 - 70}{\left( \frac{15}{\sqrt{120}} \right)} \approx 1.10 \\ z_2 & = \frac{69.5 - 70}{\left( \frac{15}{\sqrt{120}} \right)} \approx -0.37 \end{align*}\]
- The associated probabilities (from a \(z-\)table) are \(0.8643\) and \(0.3557\), respectively, meaning the desired probability is \[ 0.8643 - 0.3557 = \boxed{ 0.5086 = 50.86\% } \]
Non-Normal Population
Alright, so that explains what to do if the population values follow a normal distribution.
But what if they don’t? In real-world settings, we don’t typically get to know exactly what the population distribution is.
If our population is not normally distributed, we need to ask ourselves whether we have a “large enough sample”.
Admittedly, there isn’t a single agreed-upon cutoff for “large enough”- for the purposes of this class, we will use \(n \geq 30\) to mean “large enough” and \(n < 30\) to therefore be “not large enough.”
Non-Normal Population, \(n < 30\)
If the population is non-normal, and the sample size is not large enough…
… we can’t do anything.
More specifically, there aren’t any results we can use to confidently make inferences about the population mean- there is just too much uncertainty, between the uncertainty regarding the population’s distribution and the small sample size.
Non-Normal Population, \(n \geq 30\)
If the population is non-normal, and the sample size is large enough…
… we’re still (perhaps surprisingly) in business!
It turns out that if \(n\) is large enough, \[ \frac{\overline{X} - \mu}{\sigma / \sqrt{n}} \sim \mathcal{N}(0, \ 1) \] that is, the sample mean once again has a normal sampling distribution!
In fact, this is such an important result, we give it a name:
Central Limit Theorem for the Sample Mean
Central Limit Theorem for the Sample Mean
If we have reasonably representative samples of large enough size \(n\), taken from a population with true mean \(\mu\) and true standard deviation \(\sigma\), then \[ \frac{\overline{X} - \mu}{\sigma / \sqrt{n}} \sim \mathcal{N}\left(0, \ 1 \right) \] or, equivalently, \[ \overline{X} \sim \mathcal{N}\left( \mu, \ \frac{\sigma}{\sqrt{n}} \right) \] where \(\overline{X}\) denotes the sample mean.
Worked-Out Example
Worked-Out Example 2
The temperatures collected at all weather stations in Antarctica follow some unknown distribution with unknown mean and known standard deviation 8oF. A researcher records the temperature measurements from a representative sample of 81 different weather stations, and finds the average temperature to be 26oF.
- What is the population?
- What is the sample?
- Define the random variable of interest.
- What is the probability that this observed average of 26oF lies within 1oF of the true average temperature across all weather stations in Antarctica?
- Construct a 90% confidence interval for the true average temperature across all weather stations in Antarctica.
Solutions
The population is the set of all weather stations in Antarctica.
The sample is the 81 weather stations selected by the researcher.
The random variable of interest is \(\overline{X}\), the average temperature across 81 randomly-selected weather stations in Antarctica.
Part (d): This is where things get interesting!
- Is the population normally distributed?
- No. Or, at least, we don’t know for certain, so it’s safer not to assume it is.
- Is our sample size large enough to invoke the CLT?
- Yes, since \(n = 81 \geq 30\).
- Therefore, the CLT applies and tells us that \[ \overline{X} \sim \mathcal{N}\left(\mu, \ \frac{8}{\sqrt{81}} \right) \sim \mathcal{N}\left(\mu, \ \frac{8}{9} \right) \]
Solutions
Again, what we have found is \[ \overline{X} \sim \mathcal{N}\left(\mu, \ \frac{8}{\sqrt{81}} \right) \sim \mathcal{N}\left(\mu, \ \frac{8}{9} \right) \]
We seek \(\mathbb{P}(\mu - 1 \leq \overline{X} \leq \mu + 1)\), which we first write as \[ \mathbb{P}(\overline{X} \leq \mu + 1) - \mathbb{P}(\overline{X} \leq \mu - 1) \]
Computing the necessary \(z-\)scores yields \[\begin{align*} z_1 & = \frac{(\mu + 1) - \mu}{8/9} = \frac{9}{8} \approx 1.13 \\ z_2 & = \frac{(\mu - 1) - \mu}{8/9} = -\frac{9}{8} \approx -1.13 \end{align*}\]
Solutions
- The corresponding values from the normal table are \(0.8708\) and \(0.1292\), respectively, meaning the desired probability is \[ 0.8708 - 0.1292 = \boxed{74.16\%} \]
Unknown \(\sigma\)?
Notice that in the previous worked-out example (and, indeed, in the CLT for sample means), we need information on the true population standard deviation \(\sigma\).
What happens if we don’t have access to \(\sigma\)?
Well, we encountered a somewhat similar situation in our discussion on proportions; the standard error of \(\widehat{P}\) depended on \(p\), which proves to be a problem in practice (as, again, the true value of \(p\) is often unknown).
Does anyone remember how we solved this issue in the context of population proportions?
- That’s right- we used the substitution approximation!
- Specifically, we replaced the unknown parameter (\(p\)) with a natural point estimator of it.
Unknown \(\sigma\)?
Can anyone propose a point estimator for \(\sigma\)?
That’s right; \(s\), the sample standard deviation! \[ s = \sqrt{ \frac{1}{n - 1} \sum_{i=1}^{n} (X_i - \overline{X})^2} \]
In other words, our proposition is to use confidence intervals of the form \[ \overline{x} \pm c \cdot \frac{s}{\sqrt{n}} \]
Notice, however, that this introduces additional uncertainty into the problem as \(s\) itself is a random variable (different samples result in different sample standard deviations).
It turns out that the additional uncertainty introduced is so large that we become no longer able to use the normal distribution.
Using \(s\) in place of \(\sigma\)
Firstly, recall that we used percentiles of the standard normal distribution because \[ \frac{\overline{X} - \mu}{\sigma / \sqrt{n}} \sim \mathcal{N}(0, \ 1) \]
Mathematically, what the above discussion is saying is that the distribution of \[ \frac{\overline{X} - \mu}{s / \sqrt{n}} \] is no longer normal.
It turns out that, still assuming a large enough sample size, the quantity above follows what is known as a t-distribution.
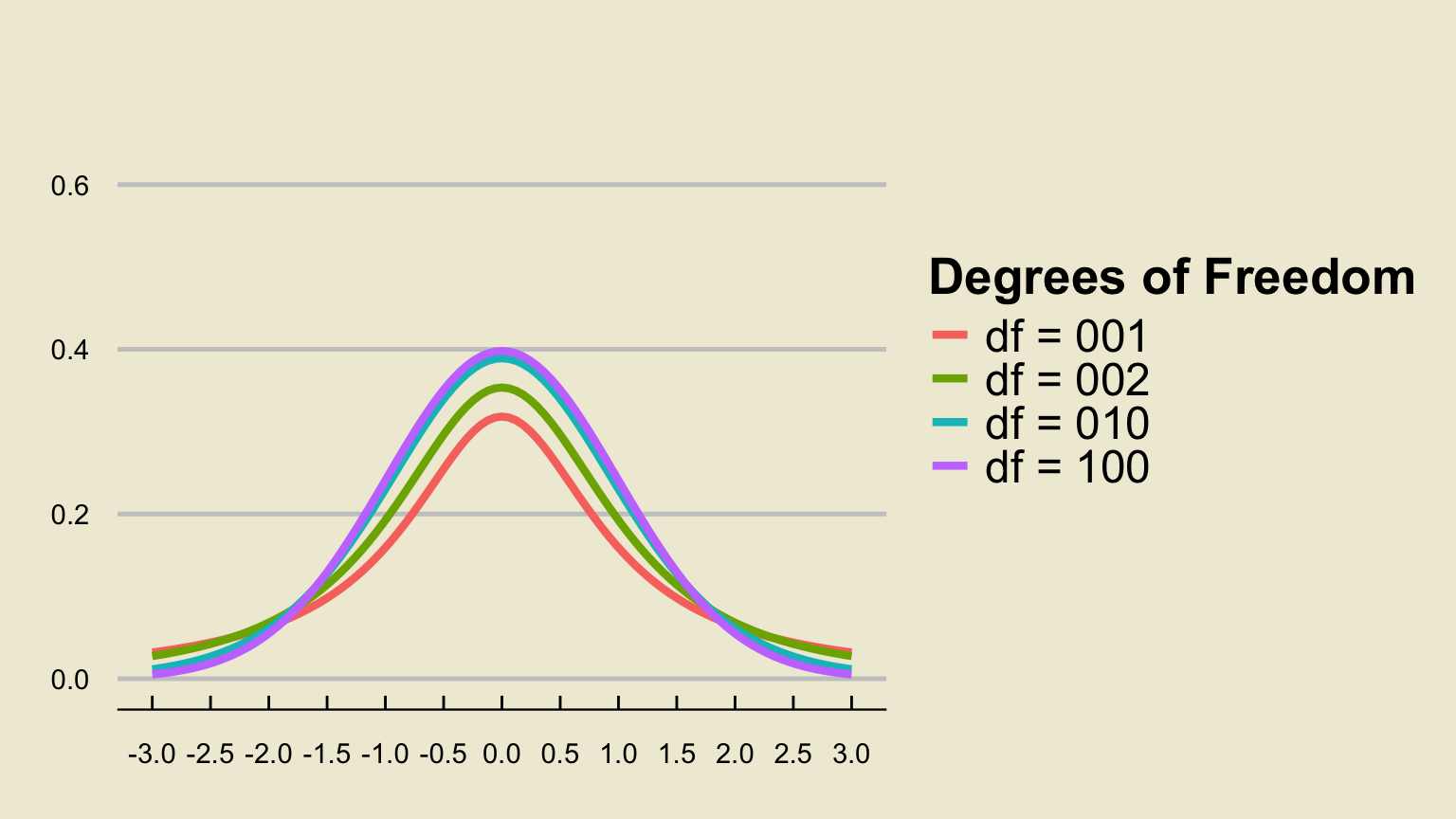
The t-distribution
The \(t-\)distribution looks very similar to the standard normal distribution in that it is centered at 1, and has a bell-like density curve.
However, one key difference is that the \(t-\)distribution is parameterized by a single parameter, called the degrees of freedom, which we abbreviate \(\mathrm{df}\).
The t-distribution
Another key property is that, for all finite degrees of freedom, the tails of the t-distribution density curve are “wider” (i.e. higher) than the tails of the standard normal density curve.
- What this means is that the t-distribution allows for higher probabilities of tail events, thereby incorporating the additional uncertainty injected into our confidence intervals by using \(s\) in place of \(\sigma\)
An interesting fact is that the t-distribution with \(\infty\) degrees of freedom is equivalent to the standard normal distribution.
- As such, with greater degrees of freedom, the t-distribution - and its percentiles - more and more closely resembles the standard normal distribution.
Back to Confidence Intervals
Here is the result we’ve been working toward: with samples of reasonably large size \(n\) from a distribution with mean \(mu\) and standard deviation \(\sigma\), \[ \frac{\overline{X} - \mu}{s / \sqrt{n}} \sim t_{n - 1} \] where \(t_{n - 1}\) denotes the \(t-\)distribution with \(n - 1\) degrees of freedom.
As such, our confidence intervals become \[ \overline{x} \pm t_{n - 1, \ \alpha} \cdot \frac{s}{\sqrt{n}} \] where \(t_{n - 1, \ \alpha}\) denotes the appropriate quantile (corresponding to our desired confidence level) of the \(t_{n - 1}\) distribution.
Worked-Out Example
Worked-Out Example 3
A sociologist is interested in performing inference on the true average monthly income (in thousands of dollars) of all citizens of the nation of Gauchonia. As such, she takes a representative sample of 49 people, and finds that these 49 people have an average monthly income of 2.25 and a standard deviation of 1.66.
- What is the population?
- What is the sample?
- Define the random variable of interest.
- Construct a 95% confidence interval for the true average monthly income (in thousands of dollars) of Gauchonian citizens.
Solutions
The population is the set of all Gauchonian residents.
The sample is the set of 49 Gauchonian residents included in the sociologist’s sample.
The random variable of interest is \(\overline{X}\), the sample average monthly income (in thousands of dollars) of a representative sample of 49 Gauchonian* residents.
Solutions (cont’d)
Part (d)
Is the population normally distributed?
- No.
Is the sample size large enough?
- Yes; \(n = 49 \geq 30\).
Do we know the population standard deviation?
- No, we only know \(s\).
Therefore, we need to use the t-distribution with \(n - 1 = 49 - 1 = 48\) degrees of freedom.
Specifically, we need to find the 2.5th percentile of the \(t_{48}\) distribution.
On Monday, during Discussion Section, you will talk about how to read a \(t-\)table (which is read slightly differently than a standard normal table).
- Please keep in mind that that will be potentially testable material on next week’s quiz, so be sure to attend Discussion Section!
Solutions (cont’d)
- For now, we’ll use Python:
Therefore, our 95% confidence interval takes the form \[ \overline{x} \pm 2.01 \cdot \frac{s}{\sqrt{49}} \] or, equivalently, \[ (2.25) \pm (2.01) \cdot \frac{1.66}{7} = 2.25 \pm 0.477 = \boxed{[1.773 \ , \ 2.727]}\]
The interpretation of this interval is much the same as our intervals for proportions:
We are 95% confident that the true average monthly income (in thousands of dollars) of Gauchonian residents is between 1.773 and 2.727.
General Flowchart
graph TB
A[Is the population Normal? . ] --> |Yes| B{{Use Normal .}}
A --> |No| C[Is n >= 30? .]
C --> |Yes| D[sigma or s? .]
C --> |No| E{{cannot proceed .}}
D --> |sigma| F{{Use Normal .}}
D --> |s| G{{Use t }}
