PSTAT 5A: Lecture 18
Correlation, and an Intro to Regression
2023-06-01
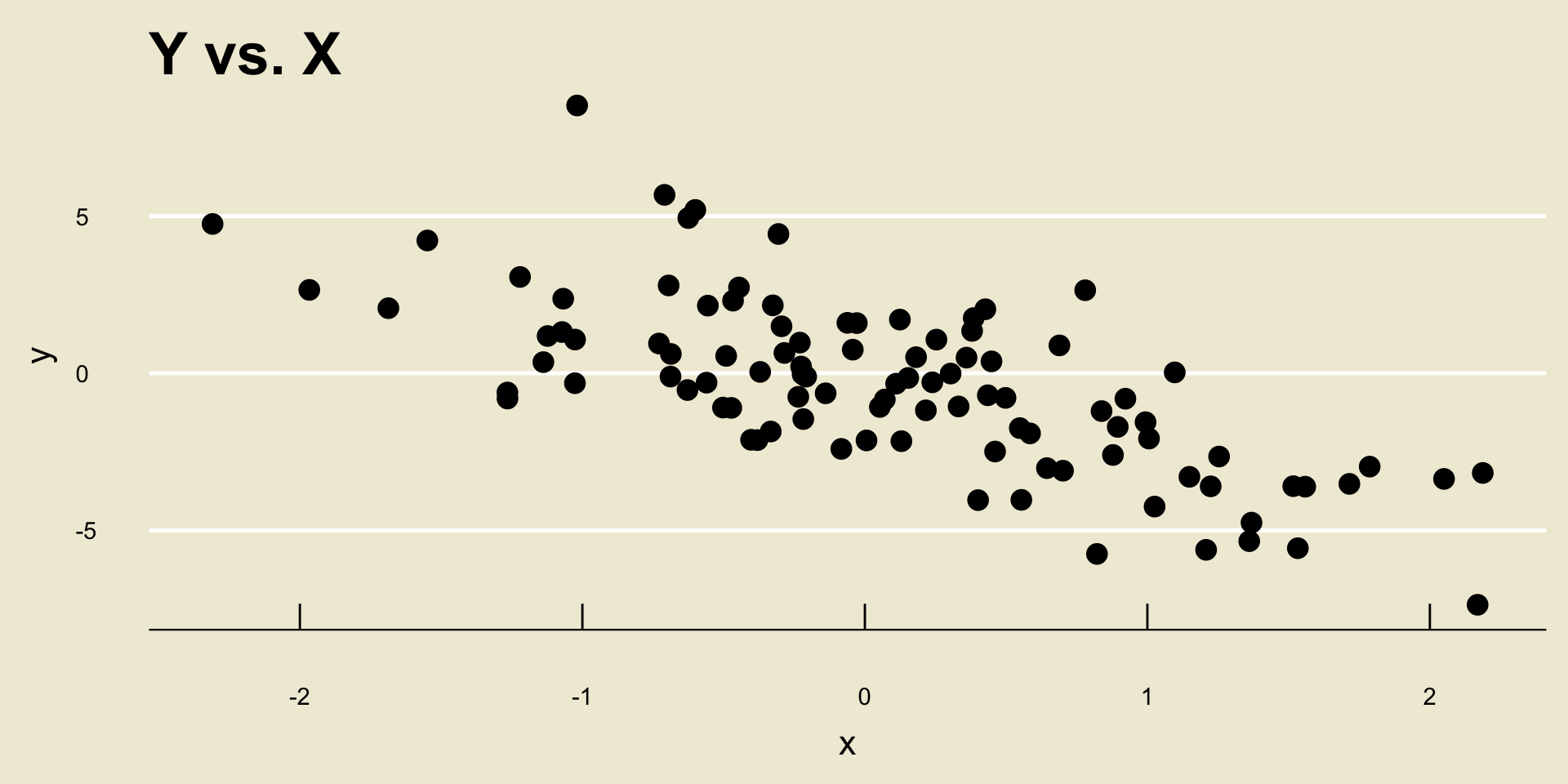
- Linear Negative Association:
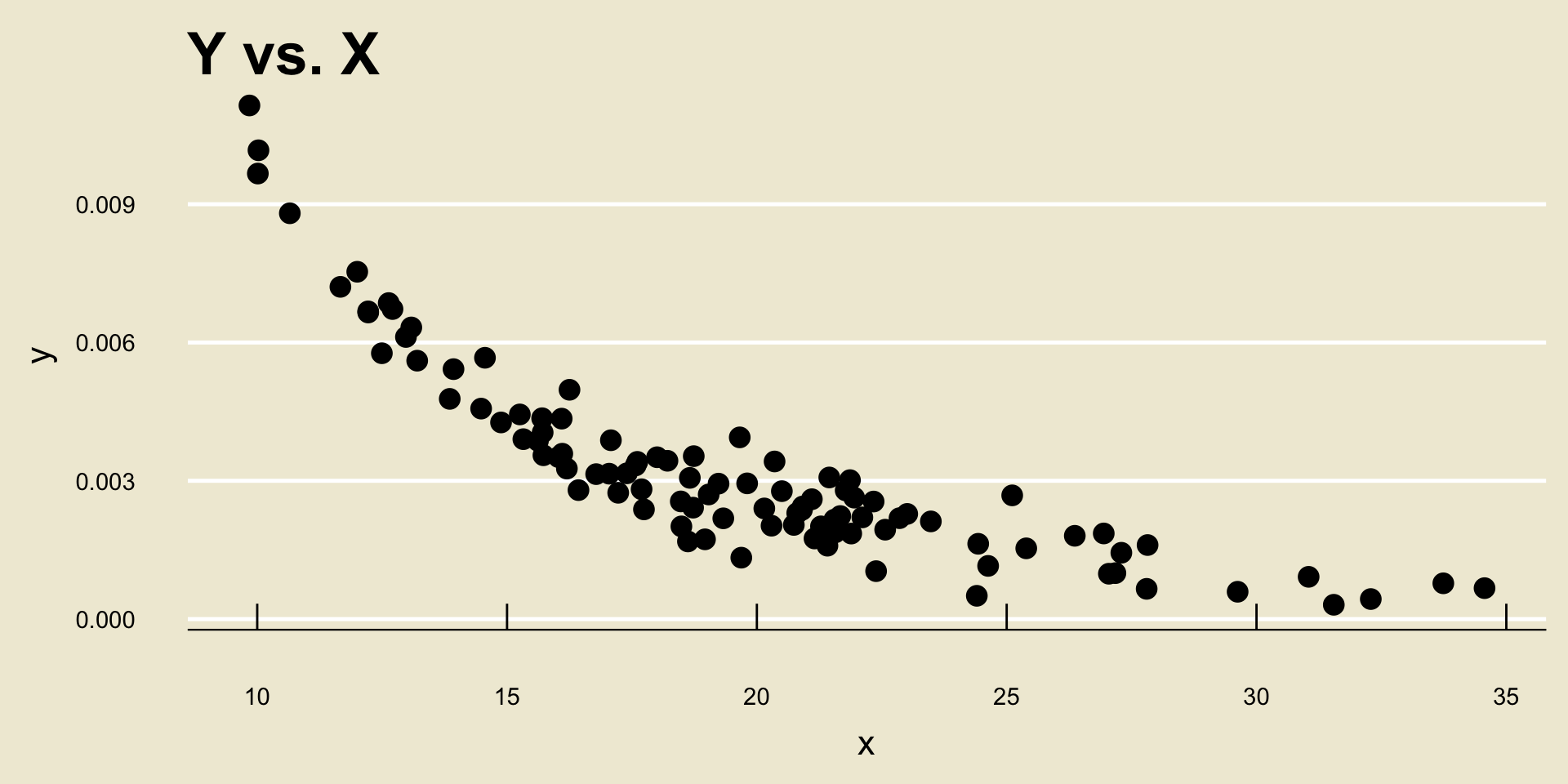
- Nonlinear Negative Association:
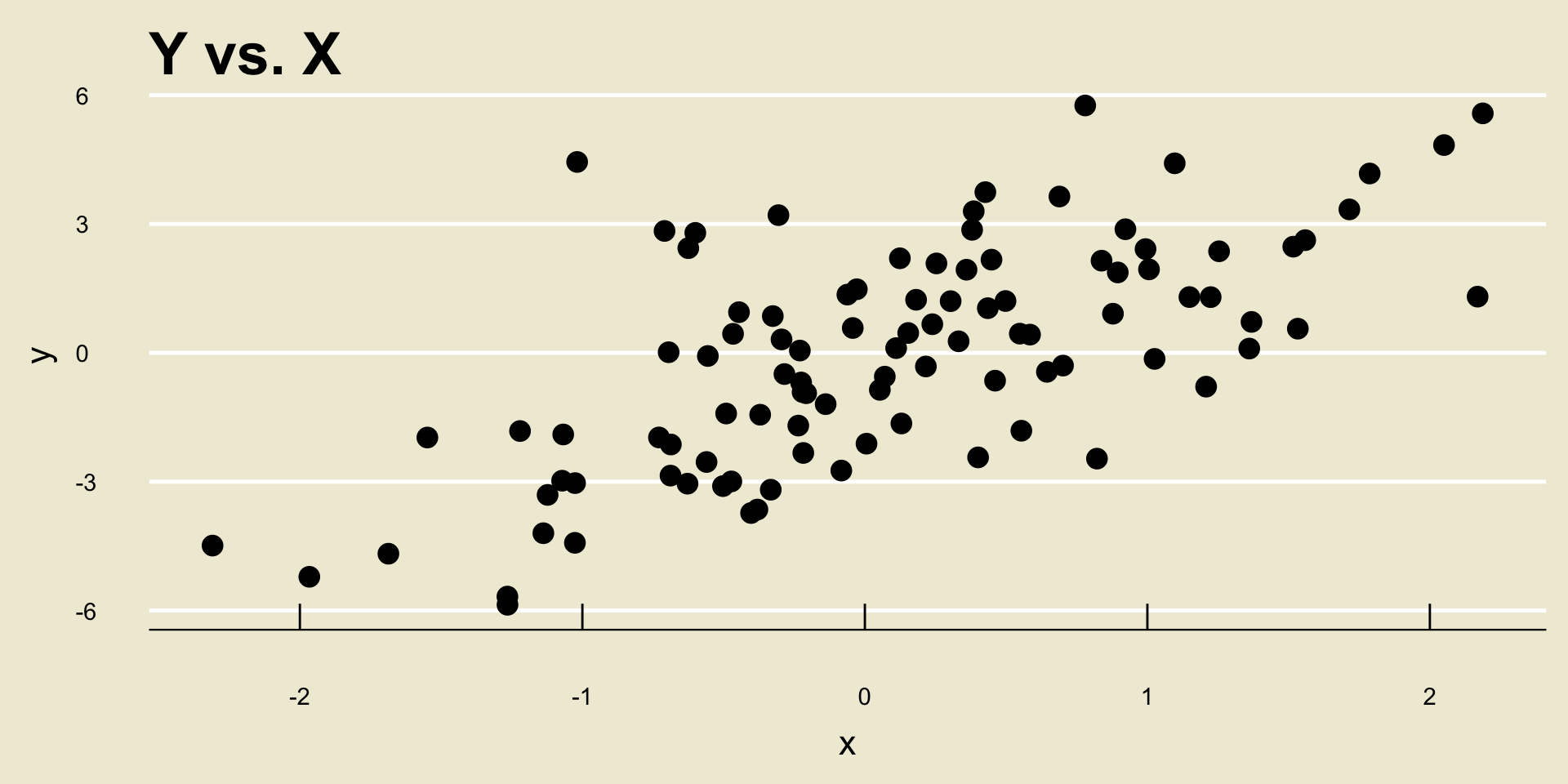
- Linear Positive Association:
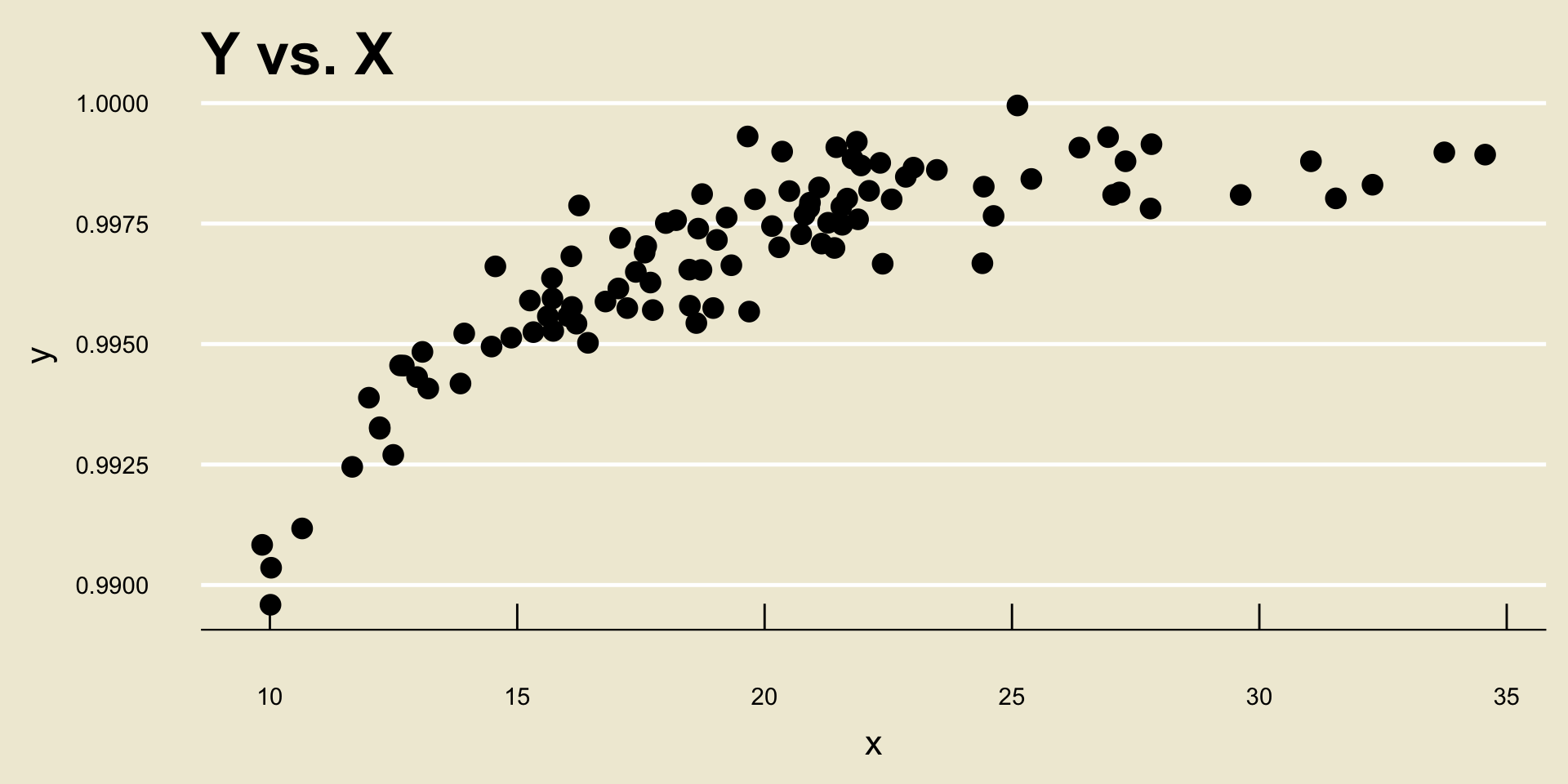
- Nonlinear Positive Association:
No Relationship
- Sometimes, two variables will have no relationship at all:
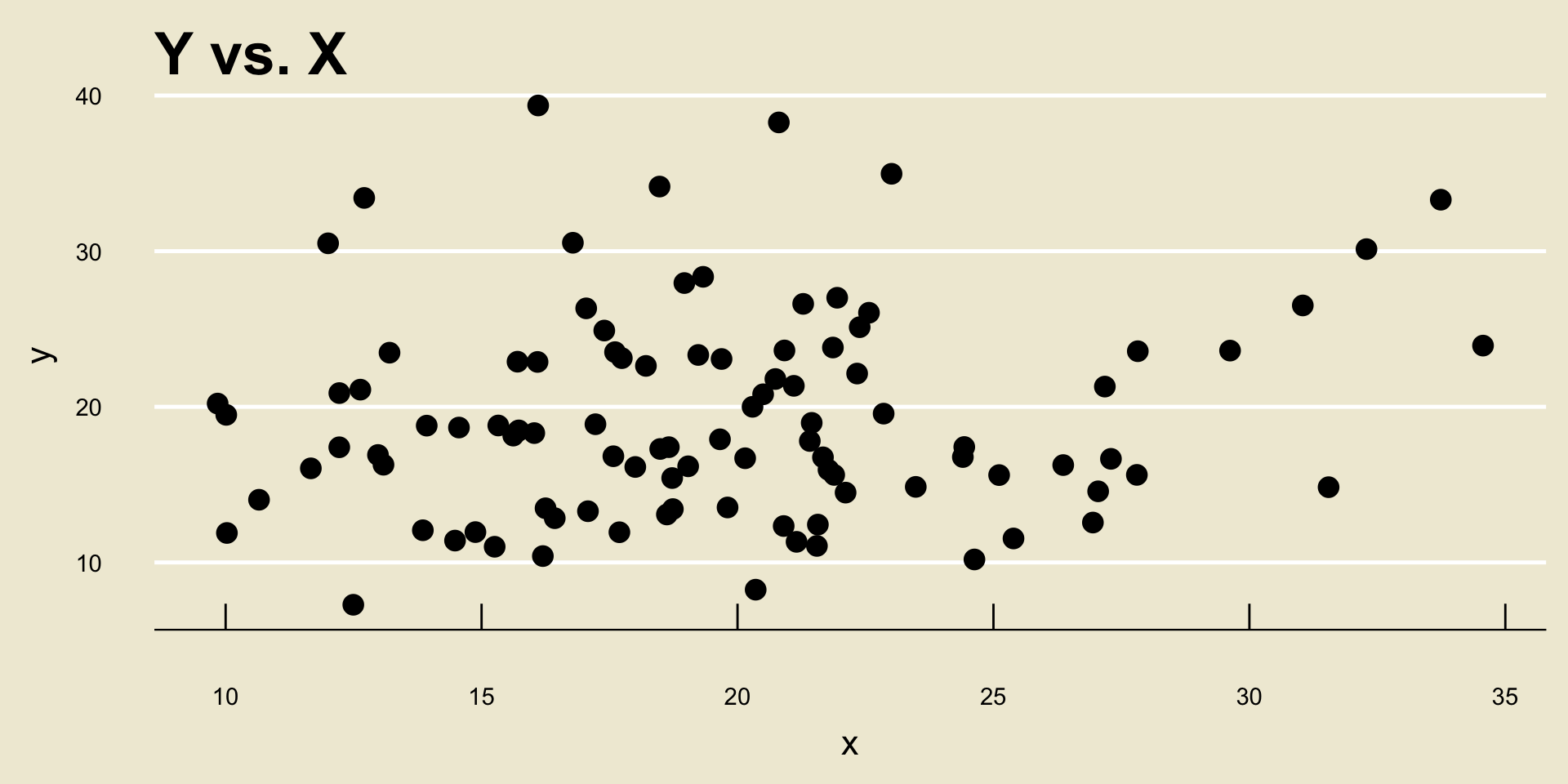
Strength of a Relationship
There is another thing to be aware of.
For example, consider the following two scatterplots:
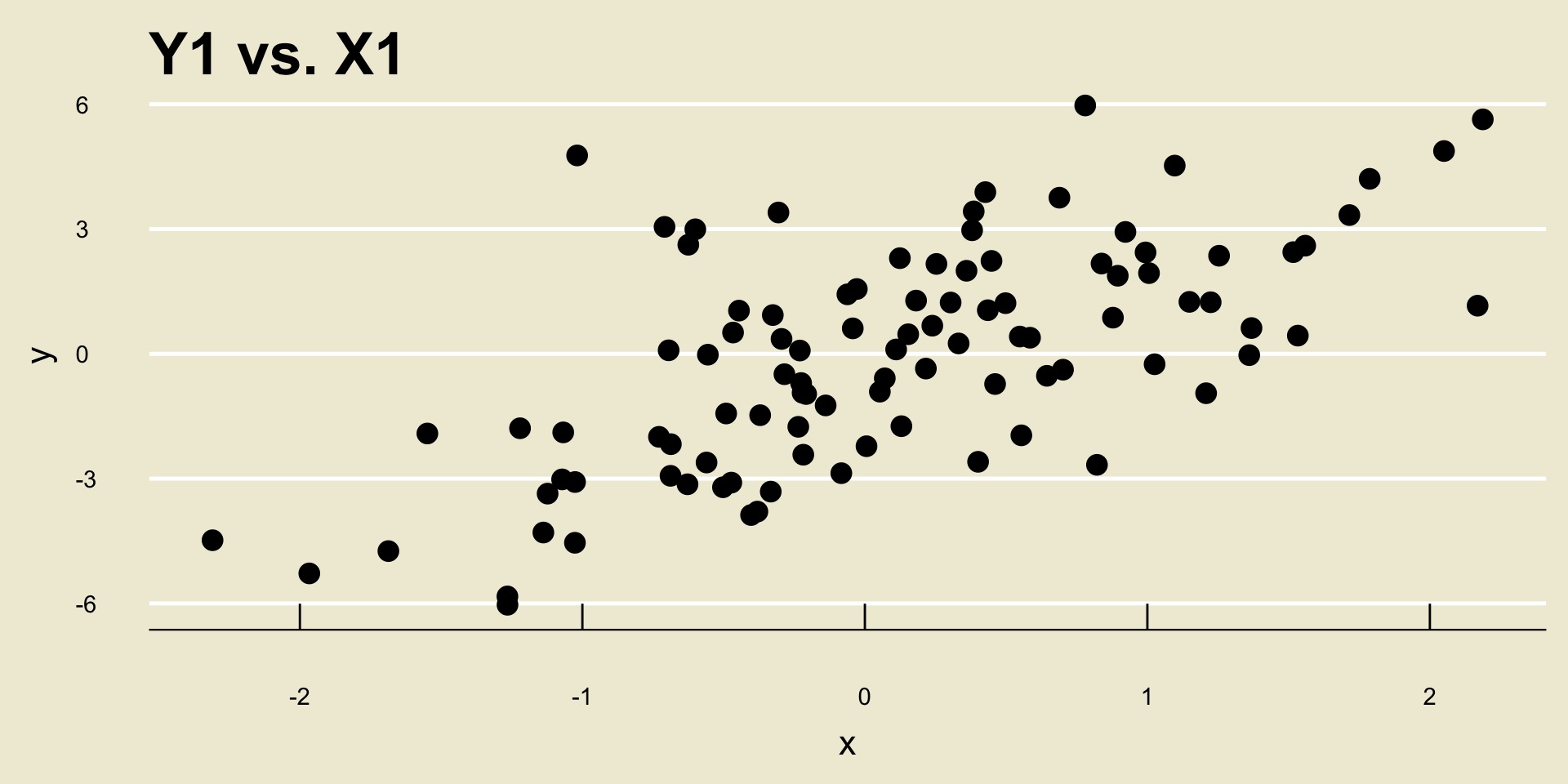
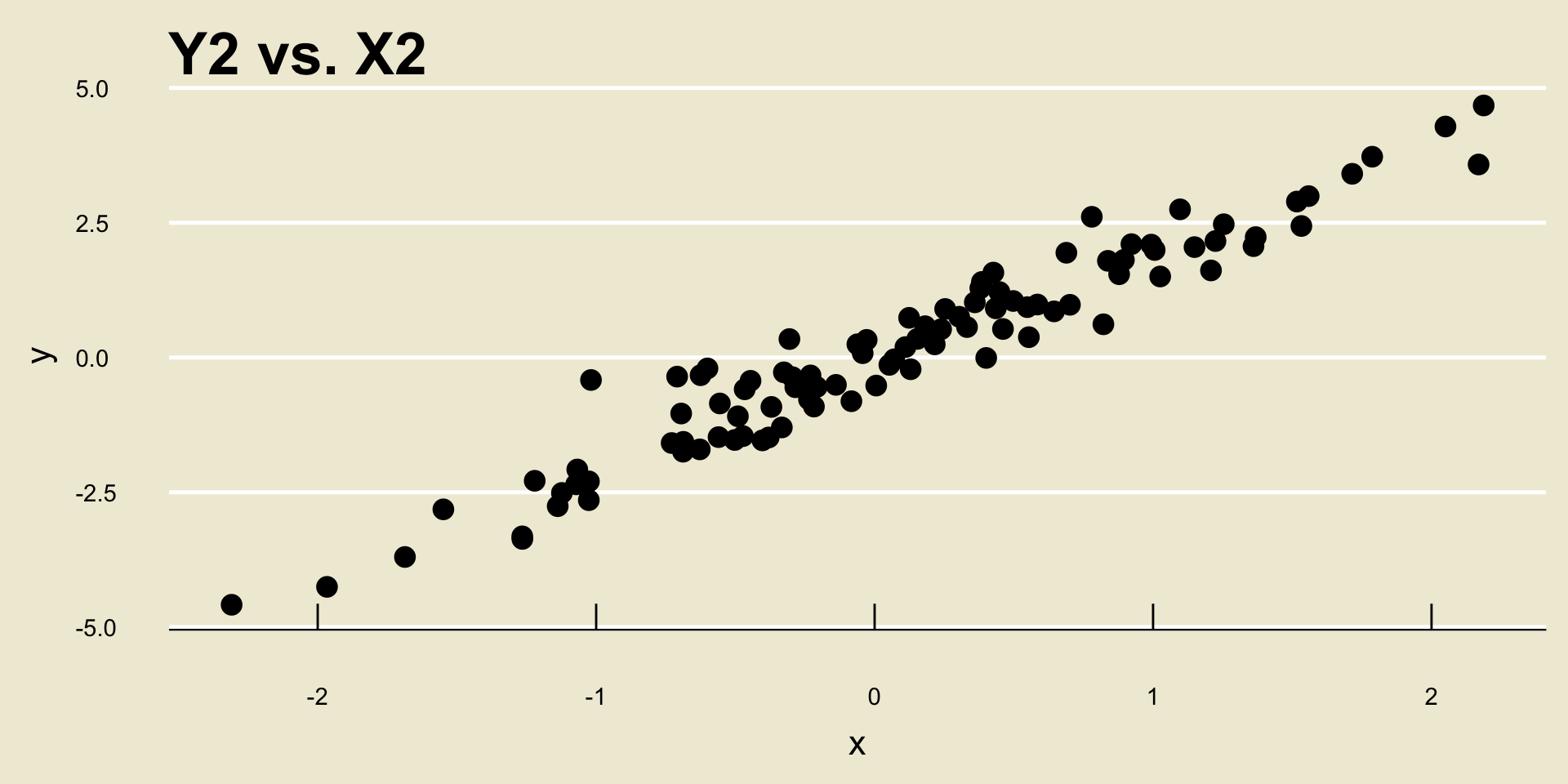
- Both scatterplots display a positive linear trend. However, the relationship between
Y2andX2seems to be “stronger” than the relationship betweenY1andX1, does it not?
Important Distinction
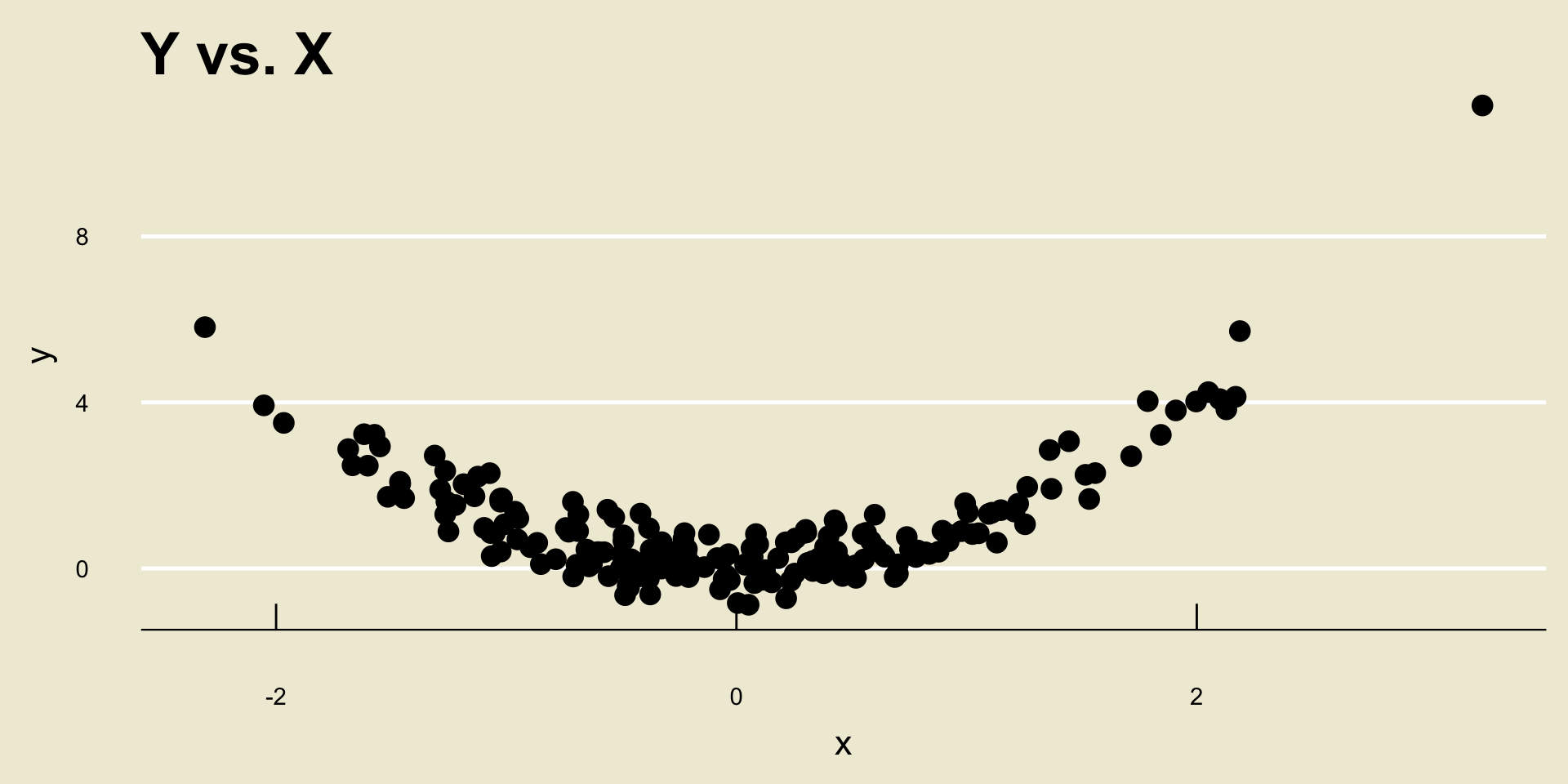
Now, something that is very important to mention is that r only quantifies linear relationships- it is very bad at quantifying nonlinear relationships.
For example, consider the following scatterplot:
Leadup
There is another thing to note about correlation.
Let’s see this by way of an example: consider the following two scatterplots:
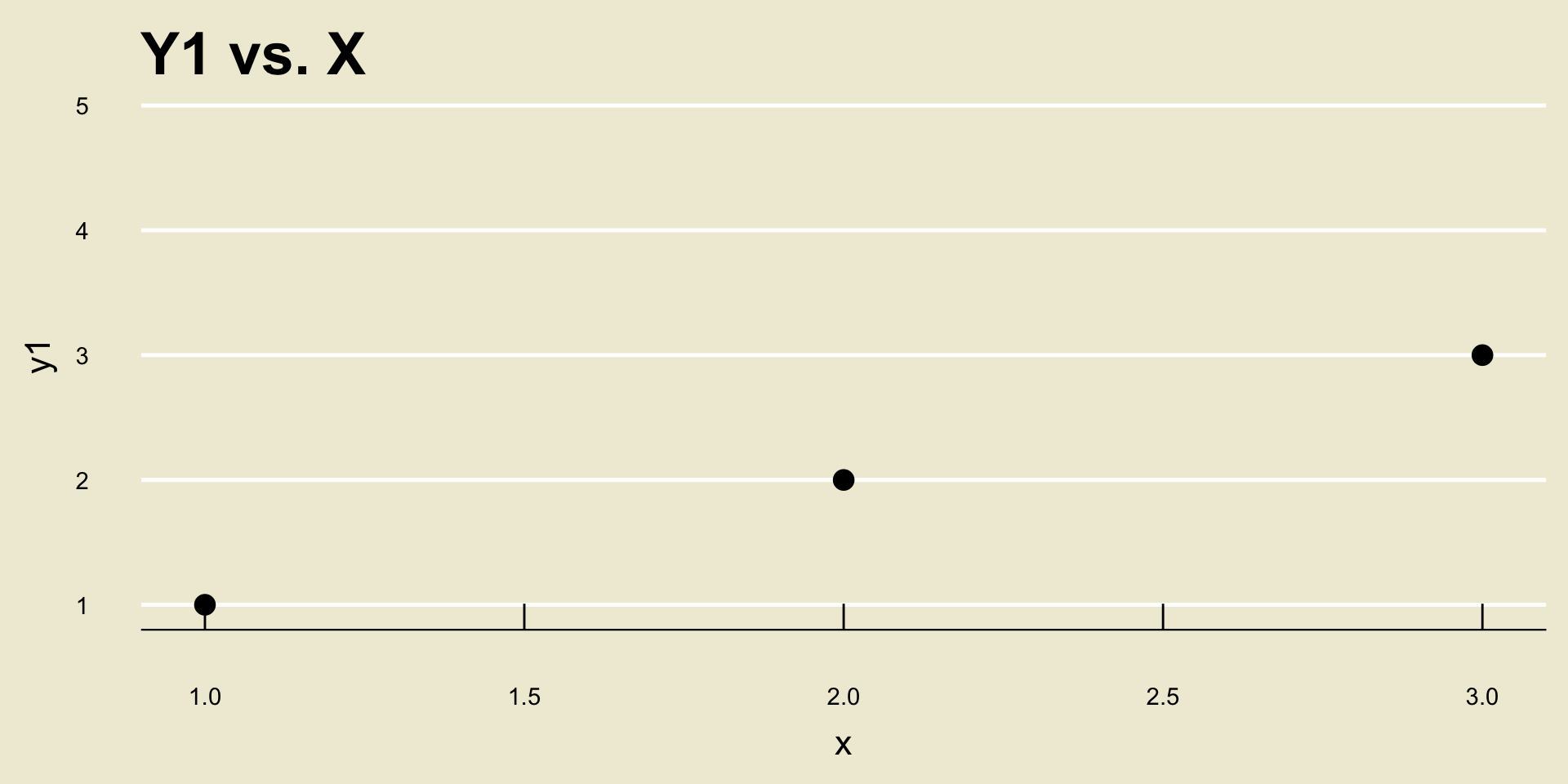
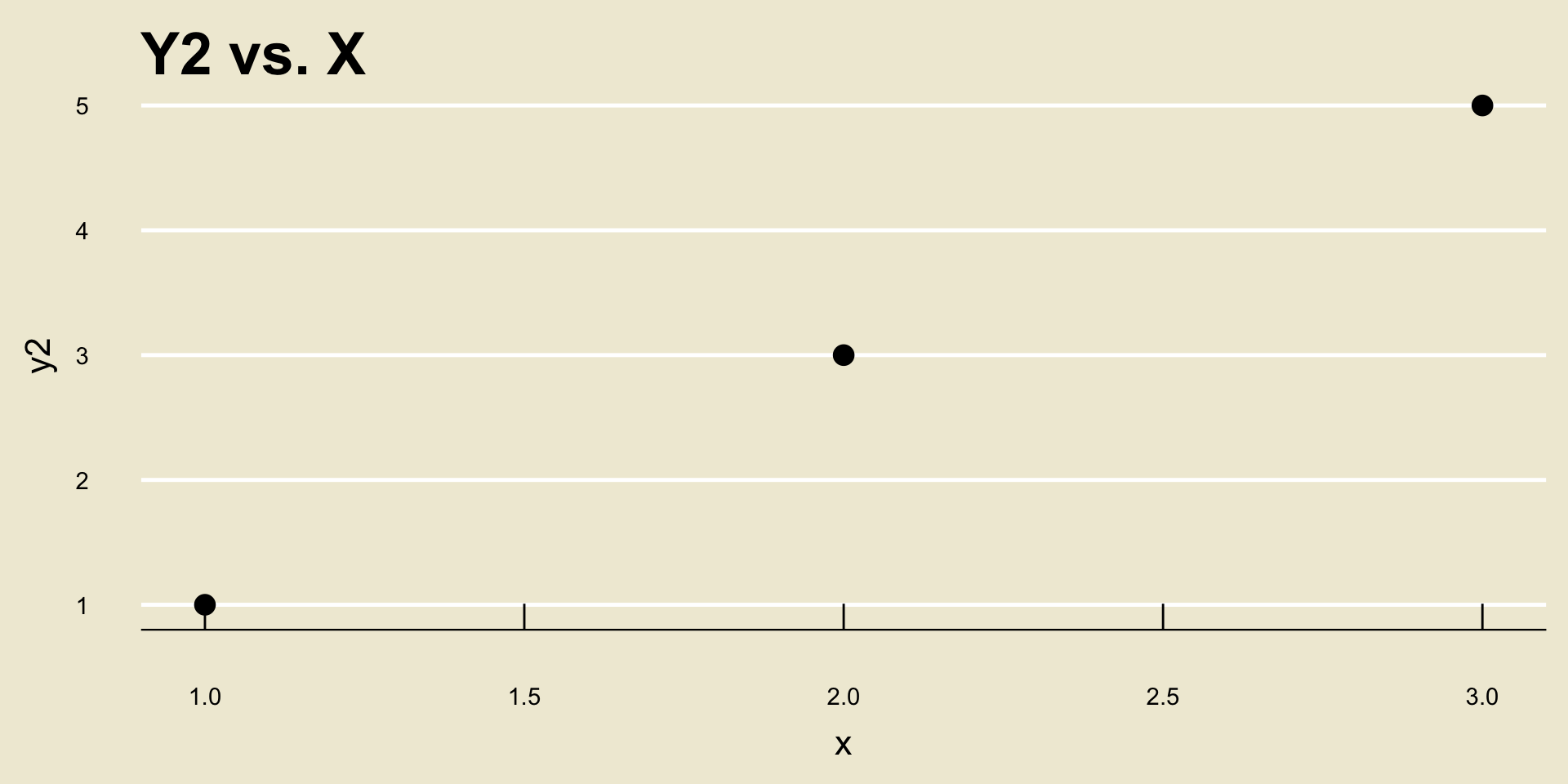
- Both cor(
X,Y1) and cor(X,Y2) are equal to 1, despite the fact that a one unit increase inxcorresponds to a different unit increase iny1as opposed toy2.
Leadup
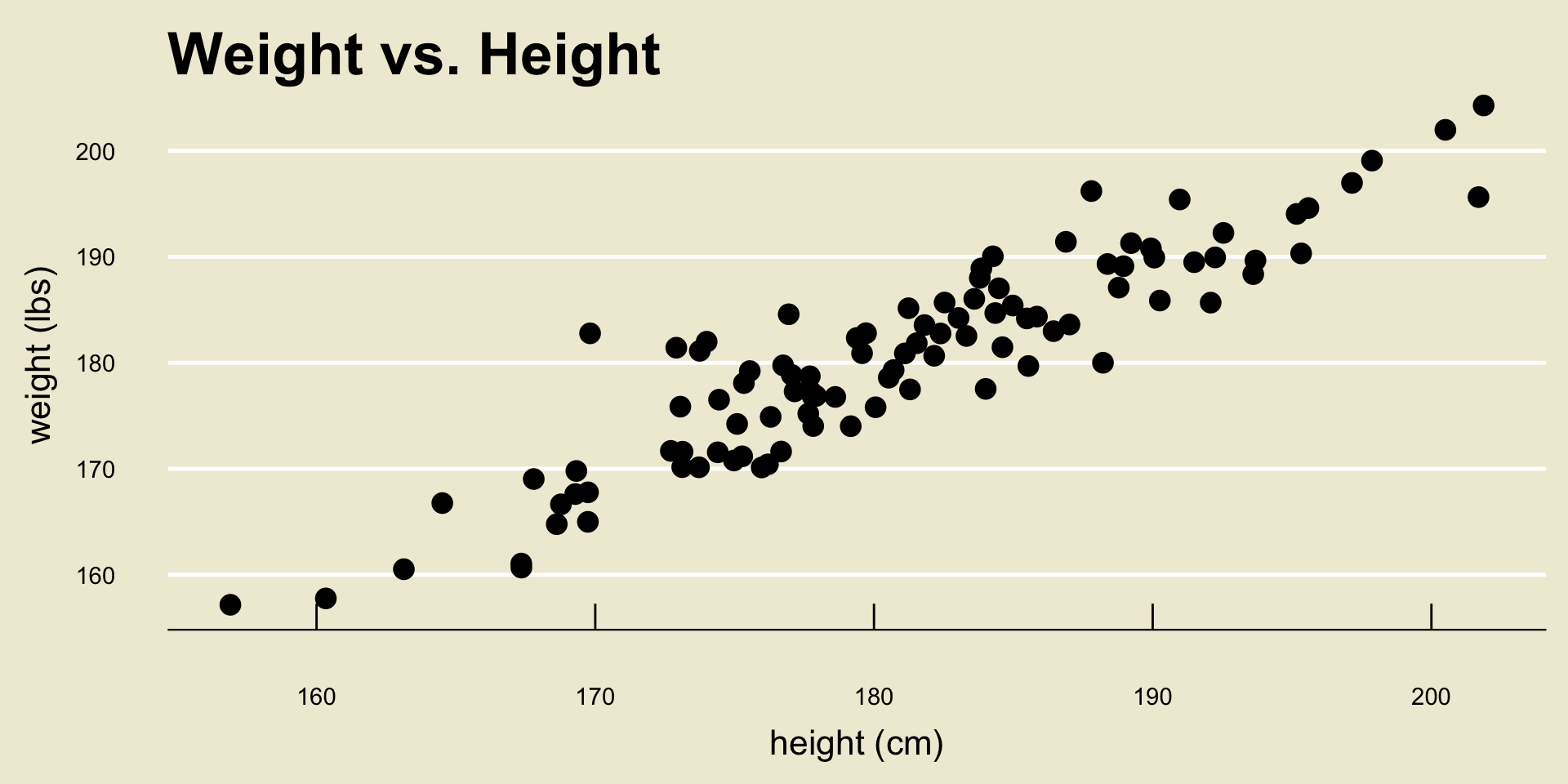
Leadup
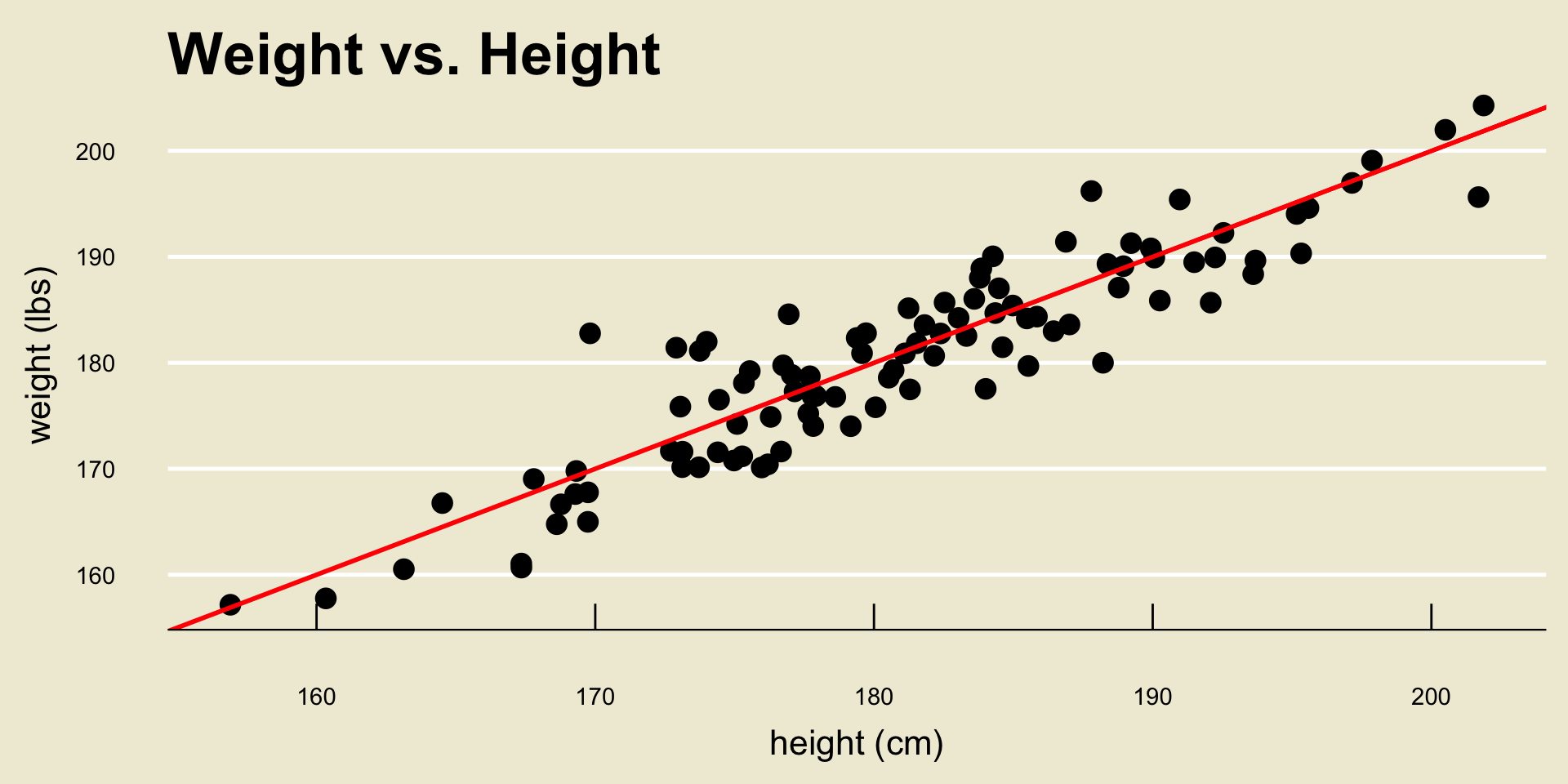
- Here, the red line represents the true relationship between
heightandweight, and any deviations from the line are assumed to be due to chance.
Goals
- Here’s a visual way of thinking about what I said on the previous slide. Consider the following scatterplot:
![]()
Goals
- We are assuming that there exists some true linear relationship (i.e. some “fit”) between
YandX. But, because of natural variability due to randomness, we cannot figure out exactly what the true relationship is.

Goals
- Finding the “best” estimate of the fit is, therefore, akin to finding the line that “best” fits the data.

Residuals
- The ith residual is defined to be the quantity \(e_i\) below:

- RSS is then just \(\displaystyle \mathrm{RSS} = \sum_{i=1}^{n} e_i^2\)
Example
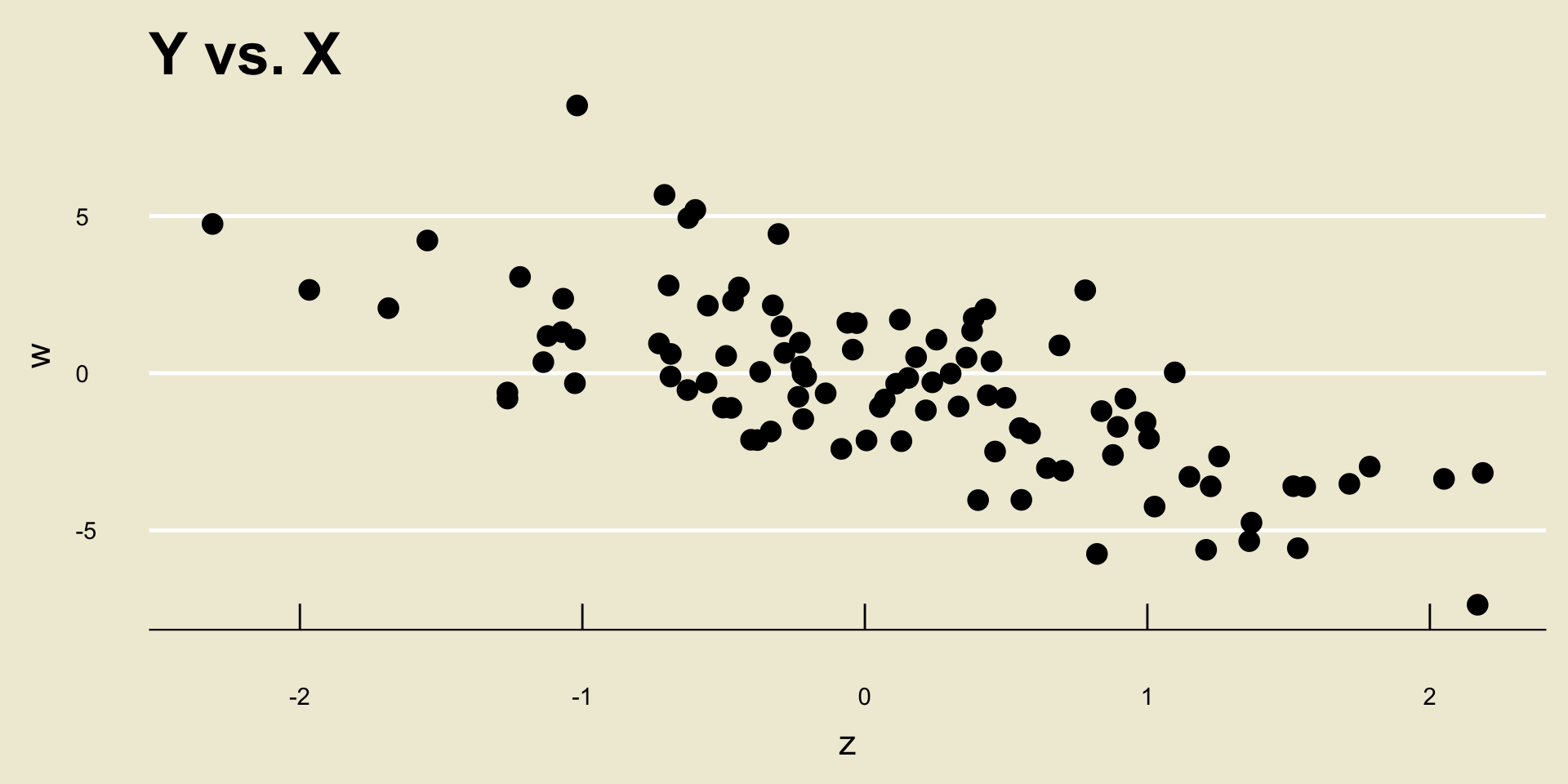
Example
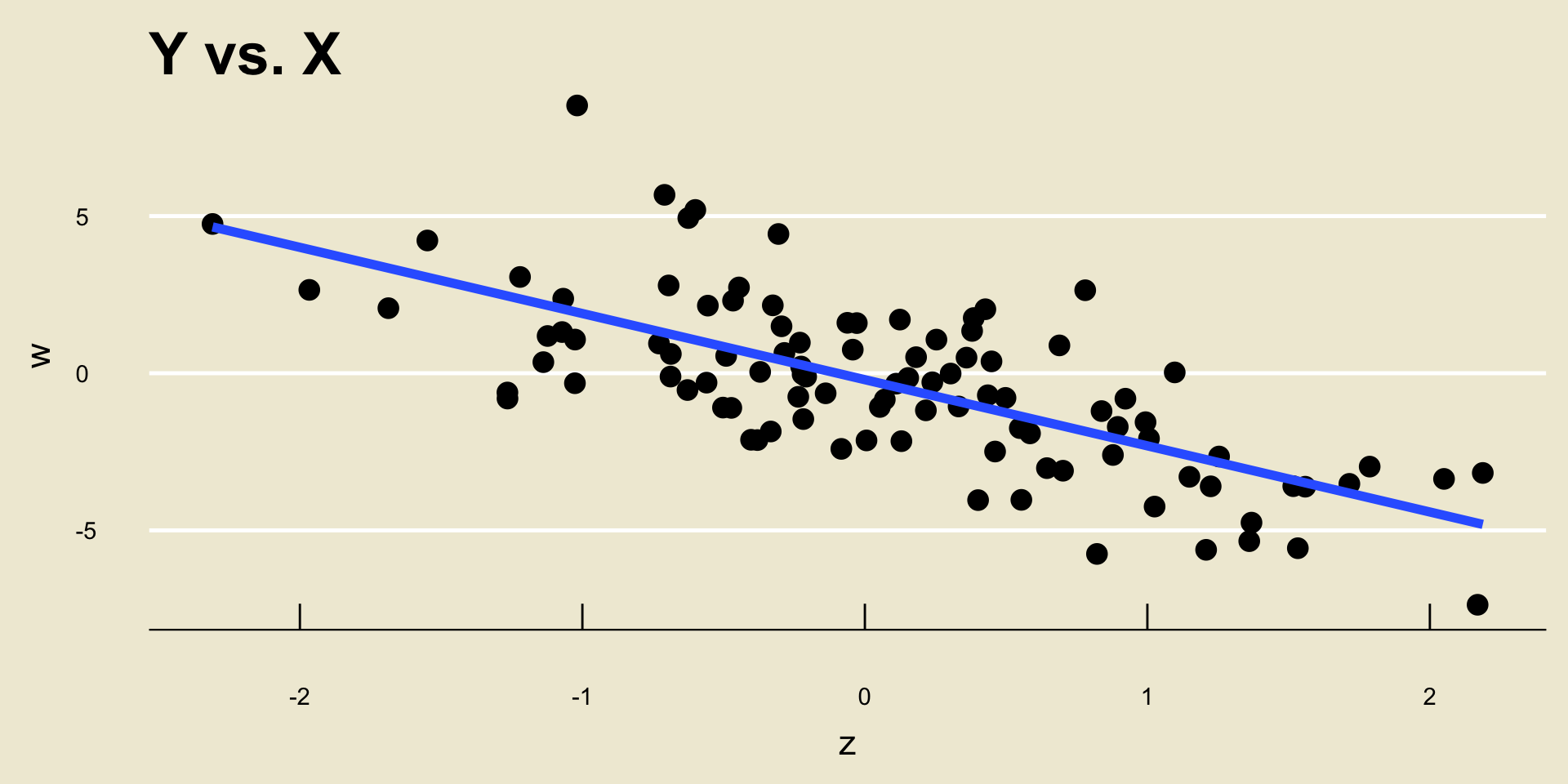
\(\widehat{\beta_0} =\) -0.2056061; \(\widehat{\beta_1} =\) -2.1049432.
I.e. the equation of the line in blue is -0.2056061 + -2.1049432 *
x.
Fitted Values
- Let’s return to our cartoon picture of OLS regression:
Fitted Values
- Notice that each point in our dataset (i.e. the blue points) have a corresponding point on the OLS regression line:

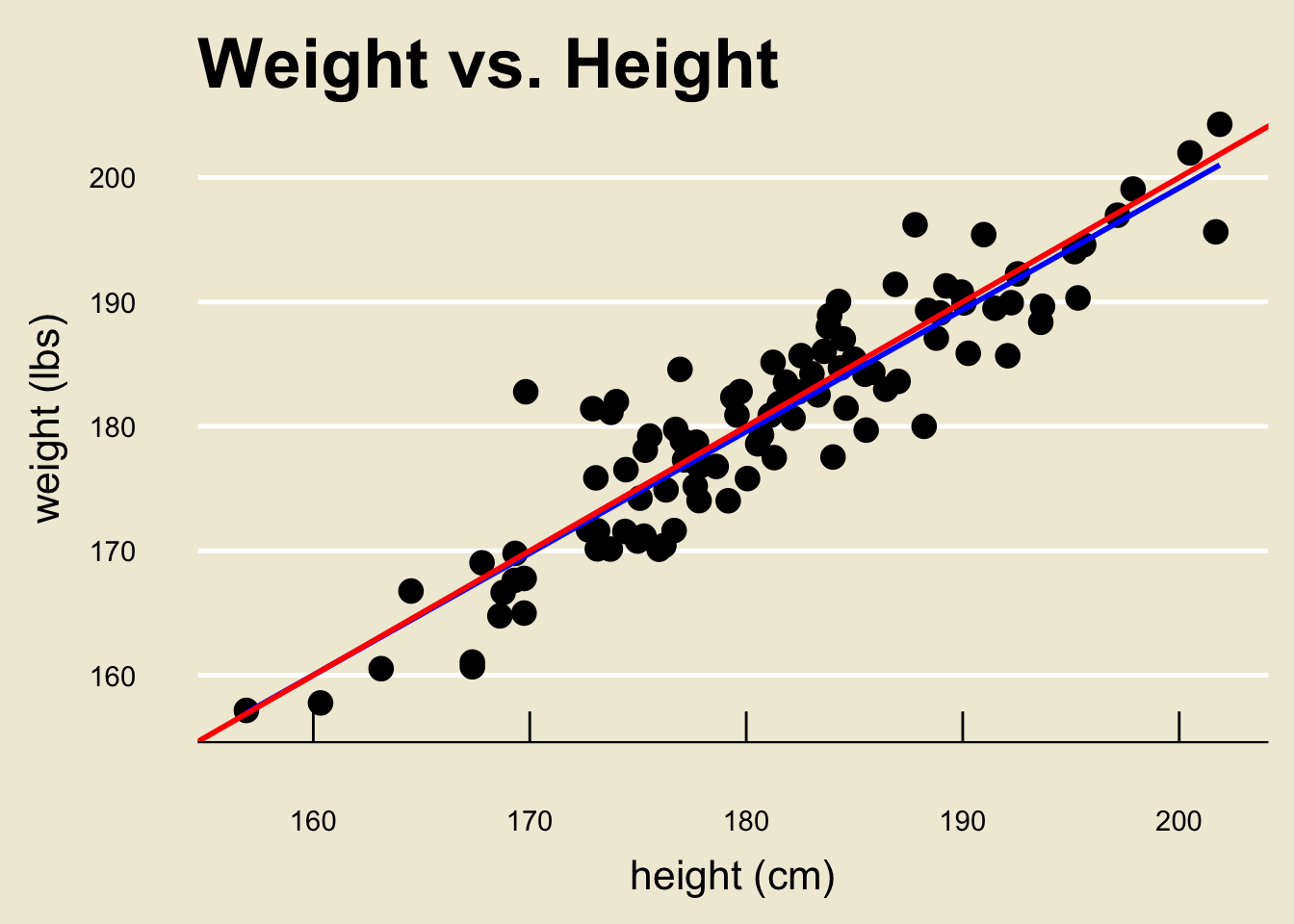
Back to height and weight
- Before we work through the math once, let’s apply this technique to the height and weight data from before.
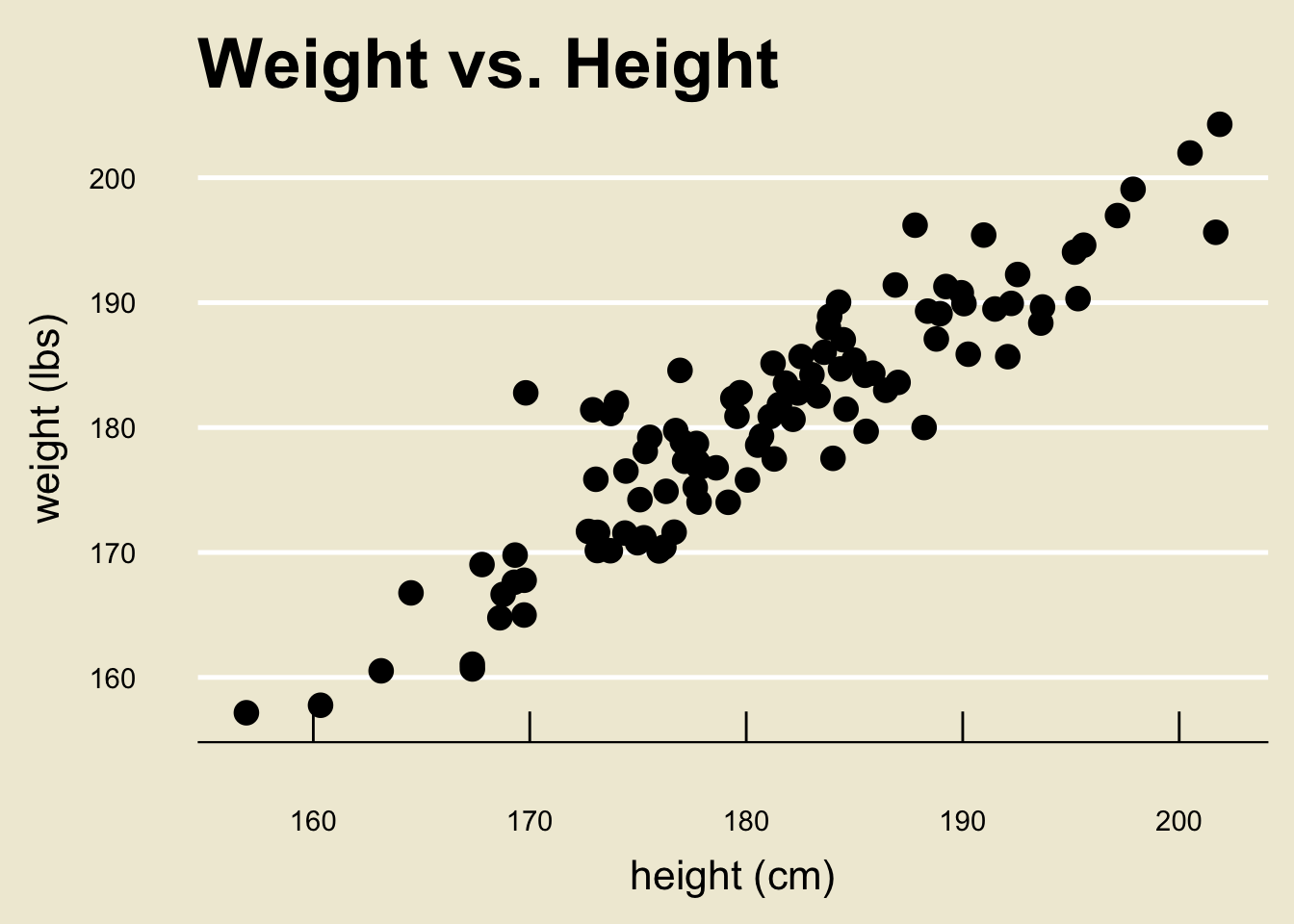
Back to height and weight
- Using a computer software, the OLS regression line can be found to be:
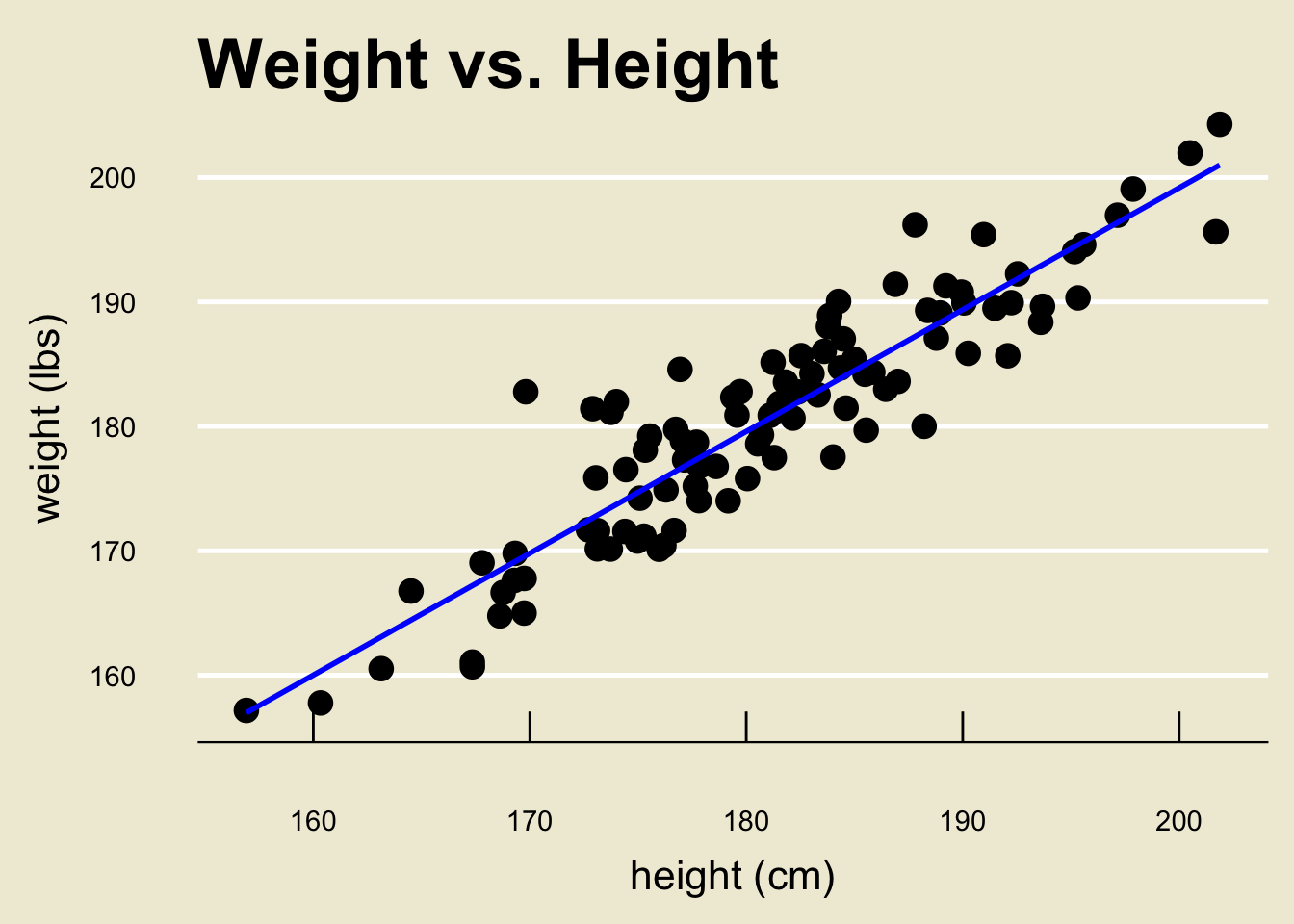
- Specifically, \(\widehat{\beta_0} =\) 3.366744 and \(\widehat{\beta_1} =\) 0.9790114
- We will return to the notion of fitted values in a bit.
\[ \widehat{\texttt{weight}} = 3.367 + 0.979 \cdot \texttt{height} \]
\[ \widehat{y} = \frac{1}{7} ( 155 - 6 x ) \]
Prediction
We can also use the OLS regression line to perform prediction.
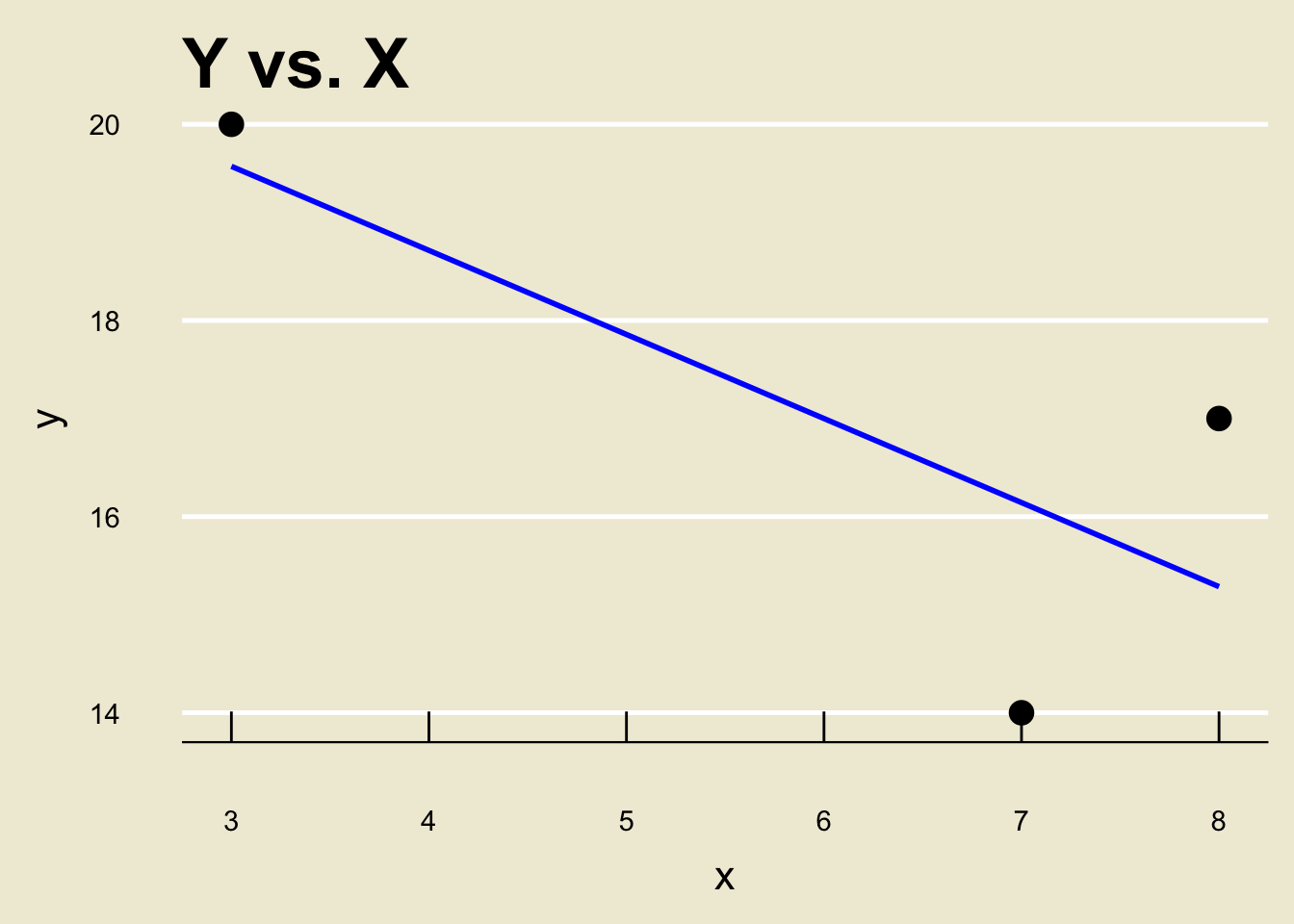
To see how this works, let’s return to our toy example:
- Notice that we do not have an
x-observation of 5. As such, we don’t know what they-value corresponding to anx-value of 5 is.
Prediction
- However, we do have a decent guess as to what the
y-value corresponding to anx-value of 5 is- the corresponding fitted value!
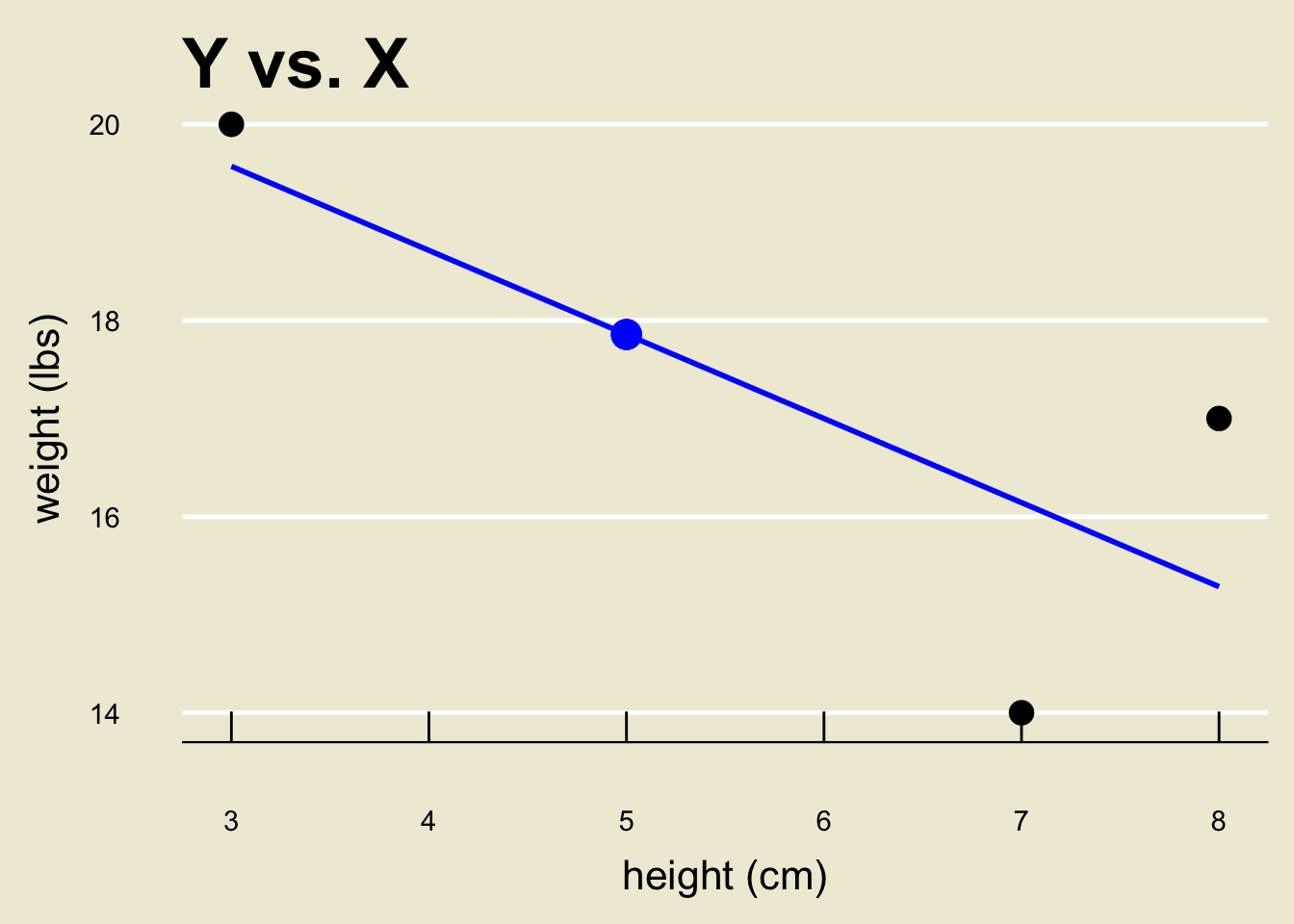
\[ \widehat{y}_5 = \frac{1}{7} (155 - 6 \cdot 5) \approx 17.857 \]
Extrapolation, and the Dangers Thereof
- Let’s look at another toy dataset:
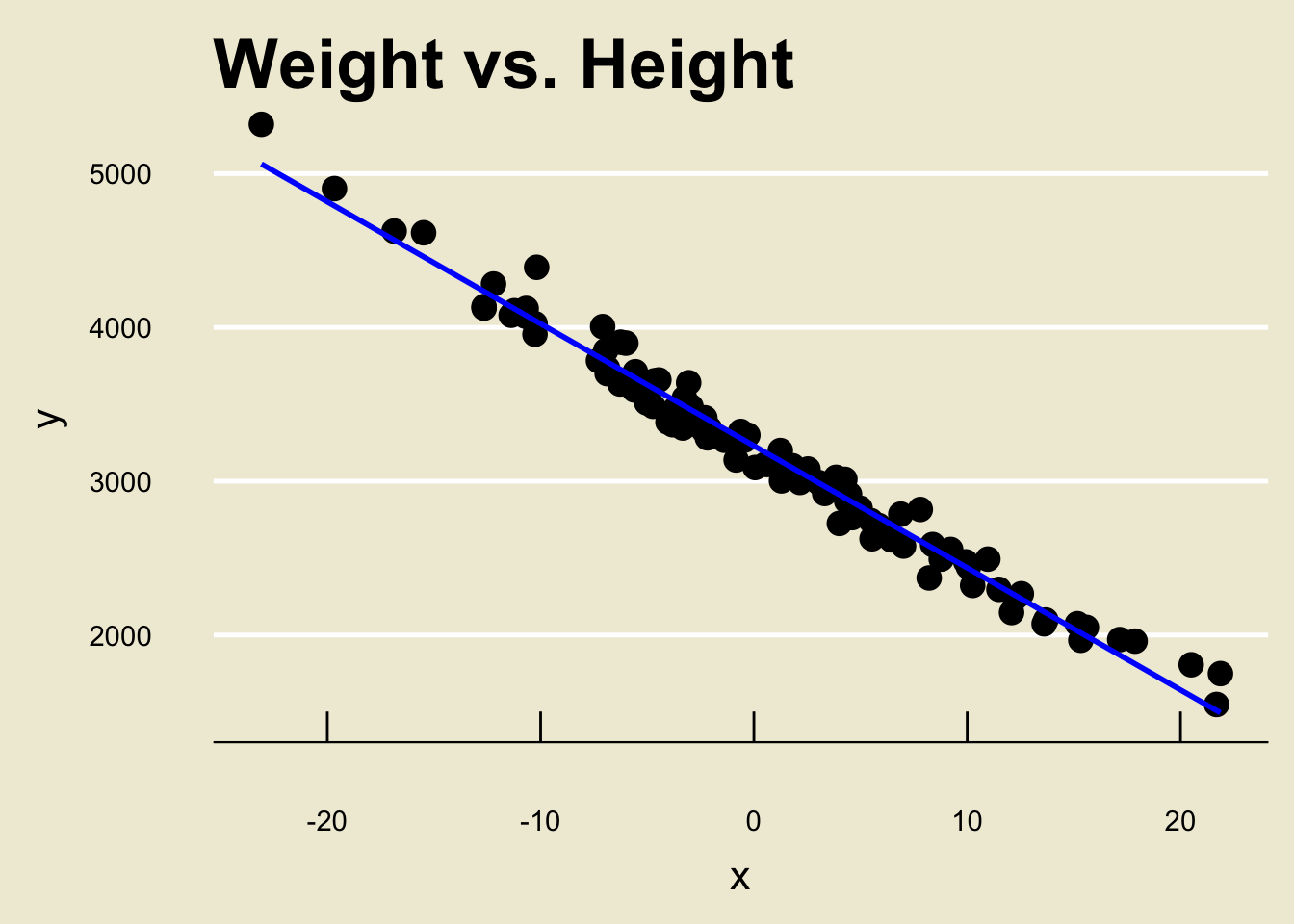
- Looks pretty linear, right?
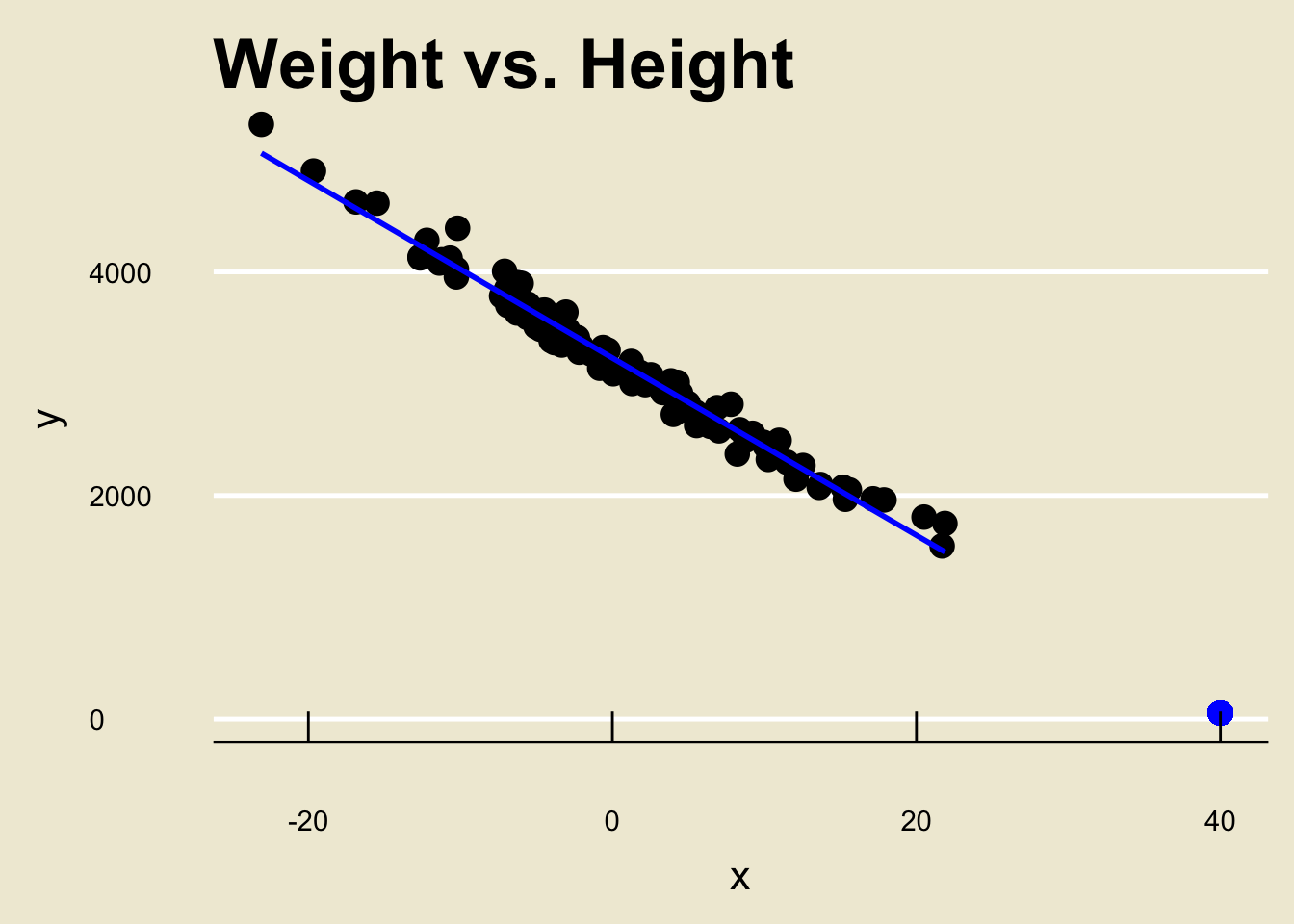
Extrapolation, and the Dangers Thereof
Say we want to predict the corresponding
yvalue of anxvalue of, 40.Following our steps from before, we would just find the fitted value corresponding to
x= 40:
Your Turn!
Exercise 2
An airline is interested in determining the relationship between flight duration (in minutes) and the net amount of soda consumed (in oz.). Letting x denote flight duration (the explanatory variable) and y denote amount of soda consumed (the response variable), a sample of size 100 yielded the following results: \[ \begin{array}{cc}
\displaystyle \sum_{i=1}^{n} x_i = 10,\!211.7; & \displaystyle \sum_{i=1}^{n} (x_i - \overline{x})^2 = 38,\!760.68 \\
\displaystyle \sum_{i=1}^{n} y_i = 14,\!3995.8; & \displaystyle \sum_{i=1}^{n} (y_i - \overline{y})^2 = 87.23984 \\
\displaystyle \sum_{i=1}^{n} (x_i - \overline{x})(y_i - \overline{y}) = 379.945 \\
\end{array} \]
- Find the equation of the OLS Regression line.
- If a particular flight has a duration of 110 minutes, how many ounces of soda would we expect to be consumed on the flight?
