graph TB
A[Is the population Normal? . ] --> |Yes| B{{Use Normal .}}
A --> |No| C[Is n >= 30? .]
C --> |Yes| D[sigma or s? .]
C --> |No| E{{cannot proceed .}}
D --> |sigma| F{{Use Normal .}}
D --> |s| G{{Use t }}
PSTAT 5A: Lecture 20
Post-MT2 Review, Part I
Ethan P. Marzban
2023-06-08
Recap of Hypothesis Testing
Setup
Consider a population, governed by some parameter \(\theta\) (e.g. a mean \(\mu\), a variance \(\sigma^2\), a proportion \(p\), etc.)
Suppose we have a null hypothesis that \(\theta = \theta_0\) (for some specified and fixed value \(\theta_0\)), along with an alternative hypothesis.
The goal of hypothesis testing is to use data (in the form of a representative sample taken from the population), and determine whether or not this data leads credence to the null in favor of the alternative.
- Recall that there are four main types of alternatives we could adopt: two-sided, lower-tailed, upper-tailed, and simple-vs-simple.
Testing a Mean
Before MT2, we discussed the framework of hypothesis testing a population proportion p.
After MT2, we discussed how to perform hypothesis testing on a population mean \(\mu\).
Let’s, for the moment, consider a two-sided test: \[ \left[ \begin{array}{rr} H_0: & \mu = \mu_0 \\ H_A: & \mu \neq \mu_0 \end{array} \right. \]
Since we know that \(\overline{X}\), the sample mean, is a relatively good point estimator of a population mean \(\mu\), we know that our test statistic should involve \(\overline{X}\) in some way.
Testing a Mean
- Specifically, we know that our test statistics are usually standardized versions of point estimators. As such, it is tempting to adopt \[ \mathrm{TS} = \frac{\overline{X} - \mu_0}{\sigma / \sqrt{n}} \] as, under certain conditions, this follows a standard normal distribution under the null (i.e. when assuming the true population mean \(\mu\) is in fact \(\mu_0\)): \[ \mathrm{TS} = \frac{\overline{X} - \mu_0}{\sigma / \sqrt{n}} \stackrel{H_0}{\sim} \mathcal{N}(0, \ 1) \]
Testing a Mean
But, we won’t always have access to the true population standard deviation \(\sigma\)! Rather, sometimes we only have access to \(s_X\), the sample standard deviation.
This leads to the following test statistic: \[ \mathrm{TS} = \frac{\overline{X} - \mu_0}{s_X / \sqrt{n}} \] which now no longer follows the standard normal distribution under the null, but rather a t-distribution with \(n - 1\) degrees of freedom: \[ \mathrm{TS} = \frac{\overline{X} - \mu_0}{s_X / \sqrt{n}} \stackrel{H_0}{\sim} t_{n - 1} \]
Sampling Distribution of \(\overline{X}\)
Test Statistic
- So, to summarize, our test statistic is: \[ \mathrm{TS} = \begin{cases} \displaystyle \frac{\overline{X} - \mu_0}{\sigma / \sqrt{n}} & \text{if } \quad \begin{array}{rl} \bullet & \text{pop. is normal, OR} \\ \bullet & \text{$n \geq 30$ AND $\sigma$ is known} \end{array} \quad \stackrel{H_0}{\sim} \mathcal{N}(0, \ 1) \\[5mm] \displaystyle \frac{\overline{X} - \mu_0}{s / \sqrt{n}} & \text{if } \quad \begin{array}{rl} \bullet & \text{$n \geq 30$ AND $\sigma$ is not known} \end{array} \quad \stackrel{H_0}{\sim} t_{n - 1} \end{cases} \]
Test
Recall our null and alternative hypotheses: \[ \left[ \begin{array}{rr} H_0: & \mu = \mu_0 \\ H_A: & \mu \neq \mu_0 \end{array} \right. \]
If an observed instance of \(\overline{X}\) is much larger than \(\mu_0\), we are more inclined to believe the alternative over the null.
- In other words, we would reject \(H_0\) for large positive values of \(\mathrm{TS}\).
However, we would also be more inclined to believe the alternative over the null if an observed instance of \(\overline{X}\) was much smaller than \(\mu_0\).
- In other words, we would reject \(H_0\) for large negative values of \(\mathrm{TS}\) as well.
Test
We combine these two cases using absolute values: \[ \texttt{decision}(\mathrm{TS}) = \begin{cases} \texttt{reject } H_0 & \text{if } |\mathrm{TS}| > c \\ \texttt{fail to reject } H_0 & \text{otherwise}\\ \end{cases} \] for some critical value \(c\).
The critical value will depend not only on the confidence level, but also the sampling distribution of \(\overline{X}\).
Specifically, as we have previously seen, it will be the appropriate percentile (“appropriate” as dictated by the confidence level) of either the \(\mathcal{N}(0, \ 1)\) distribution or the \(t_{n - 1}\) distribution.
Critical Value
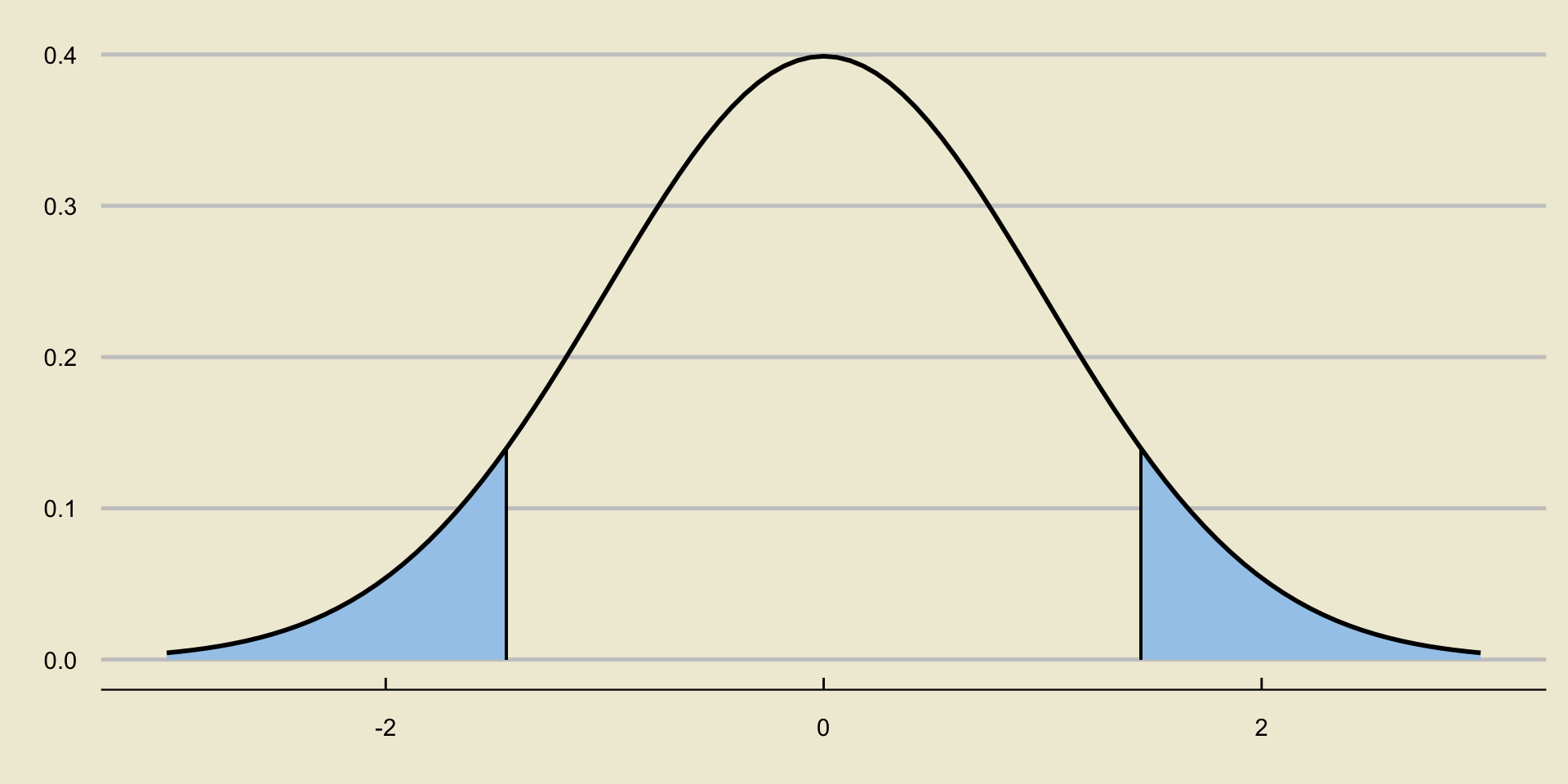
- The critical value is the positive value along the x-axis that makes the blue shaded region equal to \(\alpha\).
p-Values
We also saw how, instead of looking at critical values, we can also look at p-values.
The p-value is the probability of observing something as or more extreme (in the directino of the alternative) than what we currently observe.
As such, p-values that are smaller than the level of significance lead credence to the alternative over the null; i.e. we reject whenever \(p < \alpha\).
- Note this means that the way we compute p-values depends on the type of test (i.e. two-sided, lower-tailed, or upper-tailed) that we are conducting.
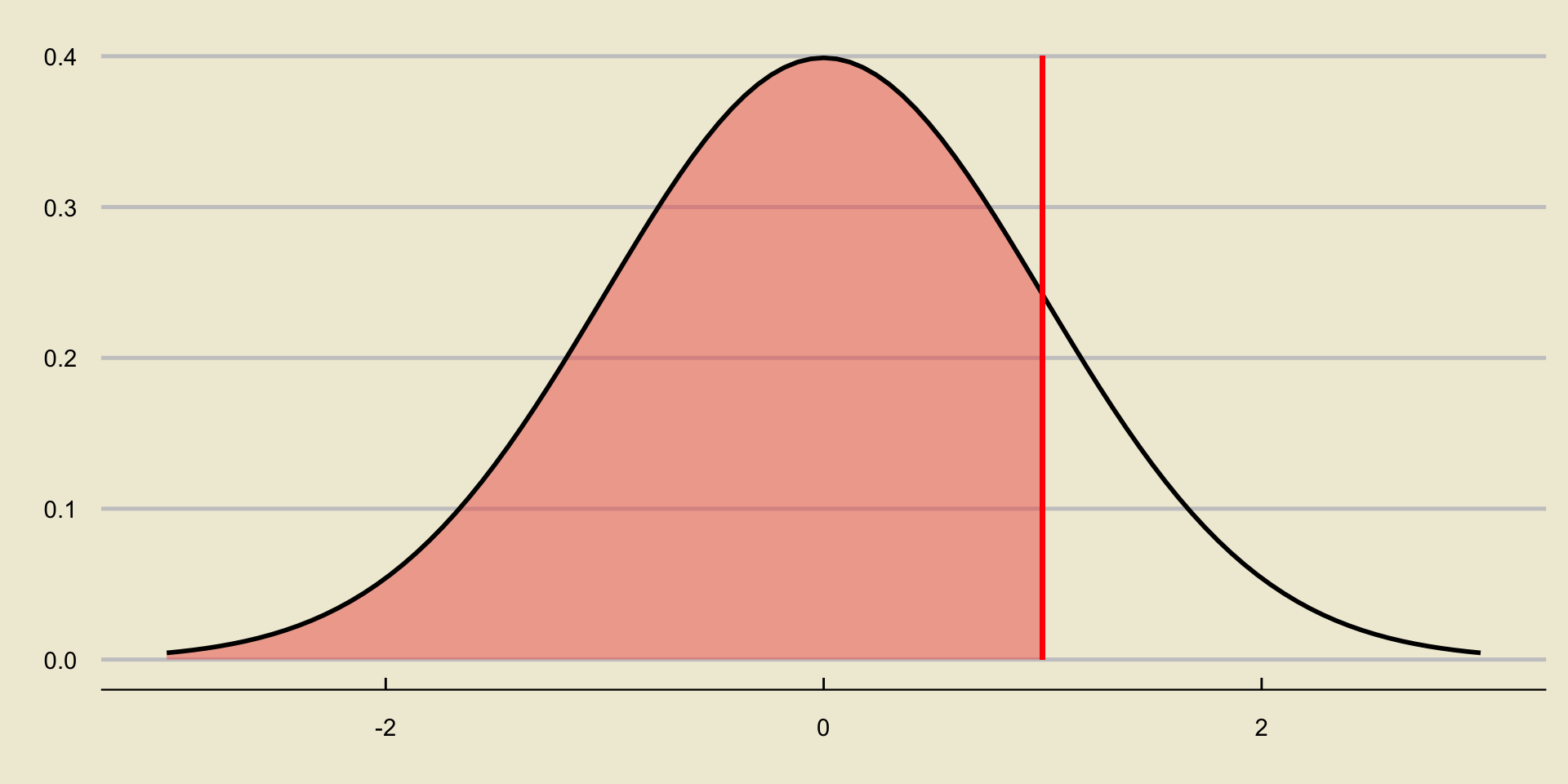
p-value; Lower-Tailed Test
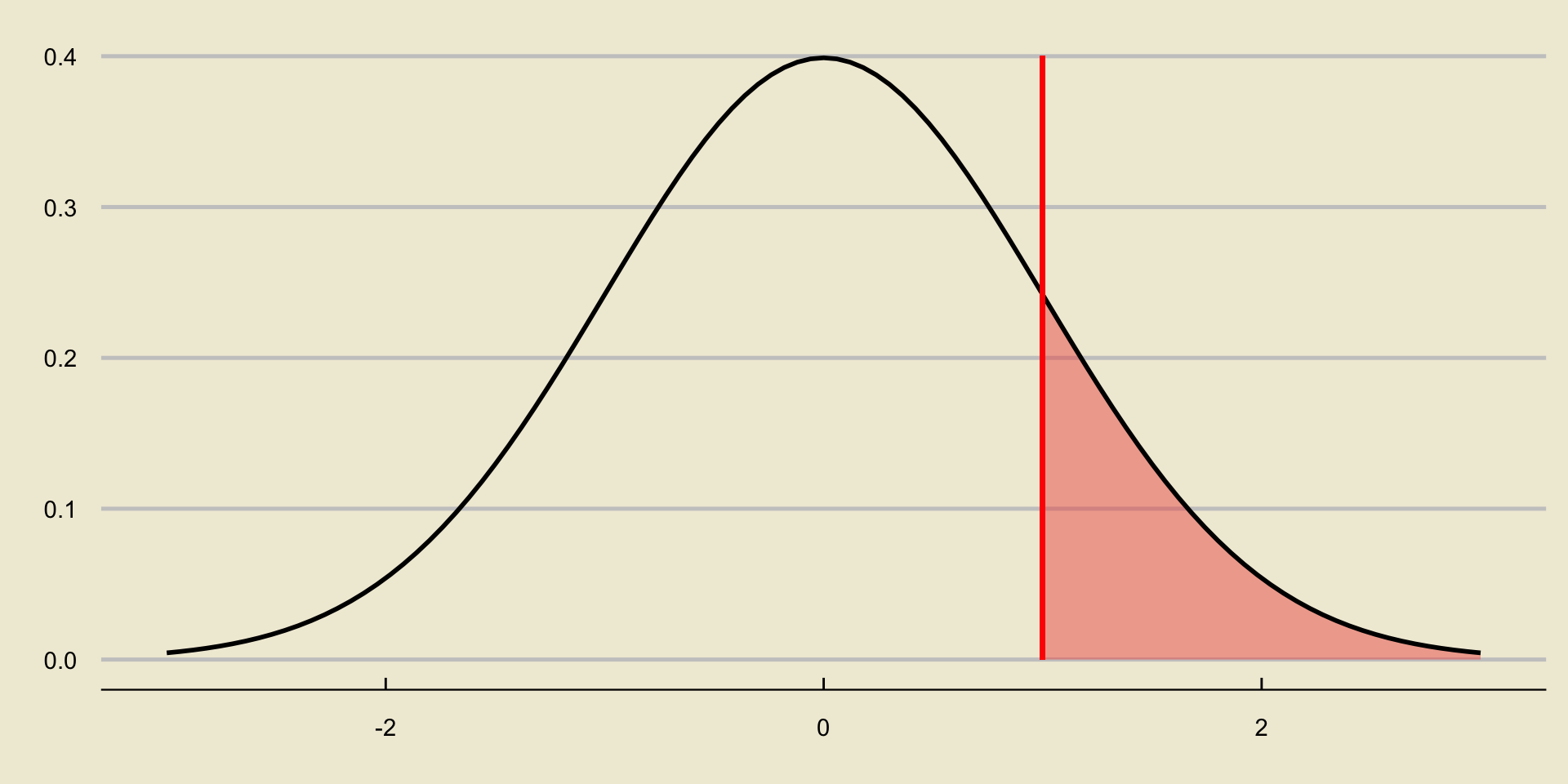
p-value; Upper-Tailed Test
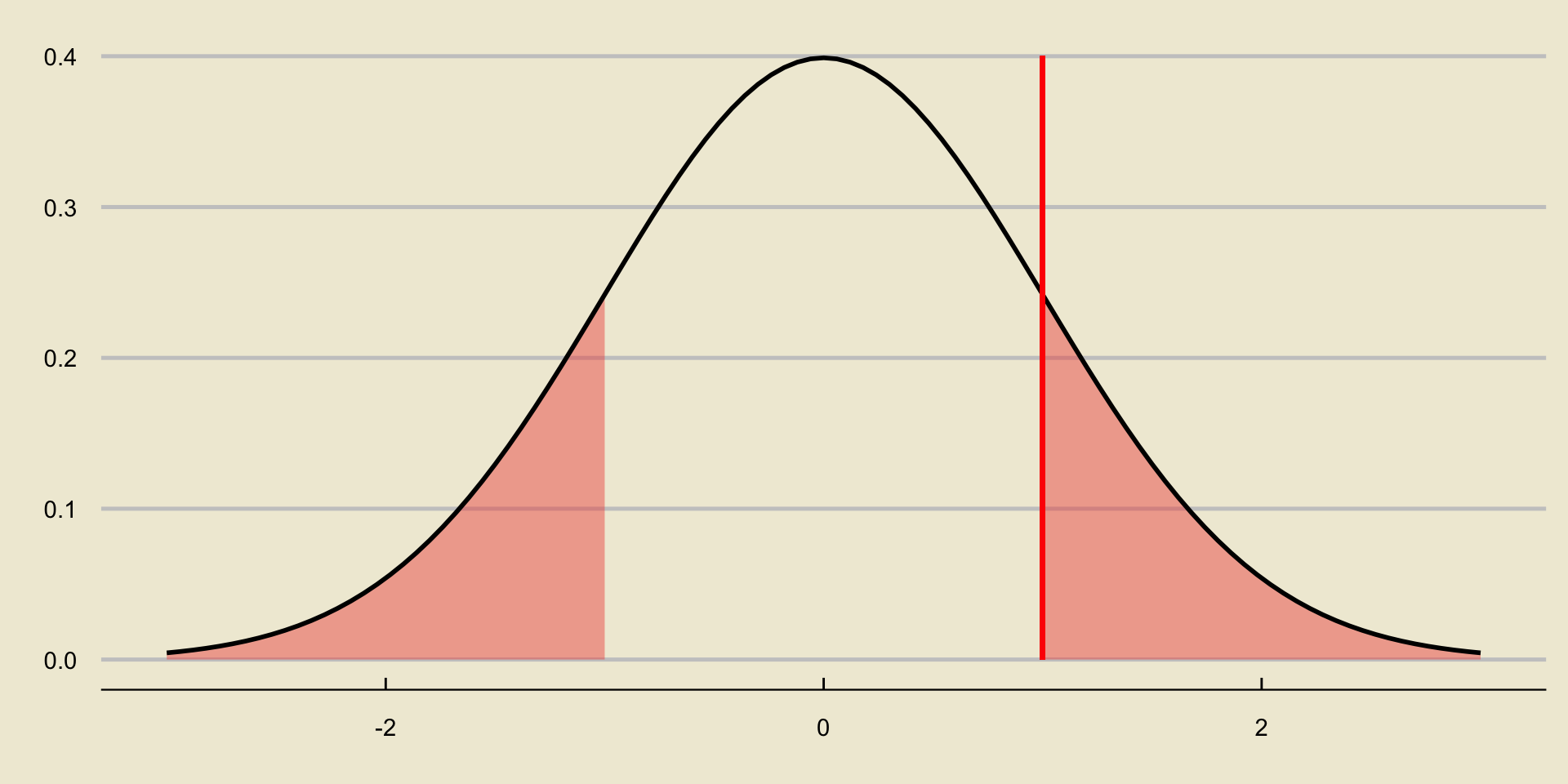
p-value; Two-Sided Test
Worked-Out Example
Worked-Out Example 1
A city official claims that the average monthly rent of a 1 bedroom apartment in GauchoVille is $1.1k. To test this claim, a representative sample of 37 1 bedroom apartments is taken; the average monthly rent of these 37 apartments is found to be $1.21k and the standard deviation of these 37 apartments is found to be 0.34. Assume we are conducting a two-sided test with a 5% level of significance.
- Define the parameter of interest.
- State the null and alternative hypotheses.
- Compute the value of the test statistic.
- Assuming the null is correct, what is the distribution of the test statistic?
- What is the critical value of the test?
- Conduct the test, and phrase your conclusions in the context of the problem.
- What code would we use to compute the p-value? Would we expect this value to be less than or greater than 5%?
Solutions
\(\mu =\) average monthly cost of a 1 bedroom apartment in GauchoVille.
\[\left[ \begin{array}{rr} H_0: & \mu = 1.1 \\ H_A: & \mu \neq 1.1 \end{array} \right. \]
Since we do not have access to the population standard deviation, we use \[ \mathrm{TS} = \frac{\overline{X} - \mu_0}{s / \sqrt{n}} = \frac{1.21 - 1.1}{0.34 / \sqrt{37}} = \boxed{ 1.97 } \]
Solutions
- We ask:
- Is the population normally distributed (i.e. are housing prices in GauchoVille normally distributed)? No.
- Is our sample size large enough? Yes; \(n = 37 \geq 30\).
- Do we have \(\sigma\) or \(s\)? We have \(s\).
- Therefore, we use a t-distribution with \(n - 1 = 37 - 1 = 36\) degrees of freedom: \[ \boxed{\mathrm{TS} \stackrel{H_0}{\sim} t_{36} } \]
Solutions
From the t-table provided on the website (which will also be provided to you during the exam), the critical value is .
Since \(|\mathrm{TS}| = |1.97| = 1.97 < 2.03\), we fail to reject the null:
At a 5% level of significance, there was insufficient evidence to reject the null hypothesis that the true monthly cost of a 1-bedroom apartment in GauchoVille is $1.1k in favor of the alternative that the true cost is not $1.1k.
- The code we would use, after importing
scipy.stats, is2 * scipy.stats.t.cdf(-1.97, 36), which we would expect to be larger than 5% as we failed to reject based on the critical value, and we only reject when p is less than \(\alpha\) (which is 5% for this problem).
Two-Sample t-Test
Two Samples
The above discussion was in regards to a single sample, taken from a single population.
What happens if we have two populations, goverend by parameters \(\theta_1\) and \(\theta_2\).
For example, suppose we want to compare the average air pollution in Santa Barbara to that in Los Angeles.
That is, given two populations (Population 1 and Population 2) with population means \(\mu_1\) and \(\mu_2\), we would like to test some claim involving both \(\mu_1\) and \(\mu_2\).
Two Samples
For this class, we only ever consider a null of the form \(H_0: \mu_1 = \mu_2\); i.e. that the two populations have the same average.
We do still have two alternative hypotheses available to us:
- \(H_A: \ \mu_1 < \mu_2\)
- \(H_A: \ \mu_1 > \mu_2\)
Remember that the trick is to reparameterize everything to be in terms of a difference of parameters, thereby reducing the two-parameter problem into a one-parameter problem.
Two-Sided
For example, suppose we are testing the following hypotheses: \[ \left[ \begin{array}{rr} H_0: & \mu_1 = \mu_2 \\ H_A: & \mu_1 \neq \mu_2 \end{array} \right. \]
We can define \(\delta = \mu_2 - \mu_1\), and equivalently re-express our hypotheses as \[ \left[ \begin{array}{rr} H_0: & \delta = 0 \\ H_A: & \delta \neq 0 \end{array} \right. \]
Test Statistic
Now, we need some sort of test statistic.
Suppose we have a (representative) sample \(x = \{x_i\}_{i=1}^{n_1}\) from Population 1 and a (representative) sample \(y = \{y_i\}_{i=1}^{n_2}\) from Population 2 (note the potentially different sample sizes!)
We have an inkling that a decent point estimator for \(\delta = \mu_2 - \mu_1\) is \(\widehat{\delta} = \overline{Y} - \overline{X}\).
Our test statistic will be some standardized form of \(\widehat{\delta}\), meaning we need to find \(\mathbb{E}[\widehat{\delta}]\) and \(\mathrm{SD}(\widehat{\delta})\).
Linear Combinations of Random Variables
Our two main results are:
- \(\mathbb{E}[aX + bY + c] = a \cdot \mathbb{E}[X] + b \cdot \mathbb{E}[Y] + c\)
- \(\mathrm{Var}(aX + bY + c) = a^2 \cdot \mathrm{Var}(X) + b^2 \cdot \mathrm{Var}(Y)\), for independent random variables \(X\) and \(Y\).
Since \(\mathbb{E}[\overline{Y}] = \mu_2\) and \(\mathbb{E}[\overline{X}] = \mu_1\), we have that \[\begin{align*} \mathbb{E}[\widehat{\delta}] & = \mathbb{E}[\overline{Y} - \overline{X}] \\ & = \mathbb{E}[\overline{Y}] - \mathbb{E}[\overline{X}] \\ & = \mu_2 - \mu_1 = \delta \end{align*}\] which effectively shows that \(\widehat{\delta}\) is a “good” point estimator of \(\delta\).
Linear Combinations of Random Variables
- Additionally, since \[ \mathrm{Var}(\overline{X}) = \frac{\sigma_1^2}{n_1}; \qquad \mathrm{Var}(\overline{Y}) = \frac{\sigma_2^2}{n_2} \] we have \[\begin{align*} \mathrm{Var}(\widehat{\delta}) & = \mathrm{Var}(\overline{Y} - \overline{X}) \\ & = \mathrm{Var}(\overline{Y}) + \mathrm{Var}(\overline{X}) \\ & = \frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2} \end{align*}\]
Test Statistic
This led us to consider the following test statistic: \[ \mathrm{TS}_1 = \frac{\overline{Y} - \overline{X}}{\sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}}} \] which, under the null, would follow a standard normal distribution if \(\overline{X}\) and \(\overline{Y}\) both followed a normal distribution.
However, in many situations, we won’t have access to the population variances \(\sigma_1^2\) and \(\sigma_2^2\). Rather, we will only have access to the sample variances \(s_X^2\) and \(s_Y^2\). Hence, we modify our test statistic to be of the form \[ \mathrm{TS} = \frac{\overline{Y} - \overline{X}}{\sqrt{\frac{s_X^2}{n_1} + \frac{s_Y^2}{n_2}}} \]
Distribution of the Test Statistic
This statistic is no longer normally distributed under the null.
It approximately follows a t distribution with degrees of freedom given by the Satterthwaite Approximation: \[ \mathrm{df} = \mathrm{round}\left\{ \frac{ \left[ \left( \frac{s_X^2}{n_1} \right) + \left( \frac{s_Y^2}{n_2} \right) \right]^2 }{ \frac{\left( \frac{s_X^2}{n_1} \right)^2}{n_1 - 1} + \frac{\left( \frac{s_Y^2}{n_2} \right)^2}{n_2 - 1} } \right\} \]
That is; \[ \mathrm{TS} \stackrel{H_0}{\sim} t_{\mathrm{df}}; \quad \text{df given by above}\]
Test
If we are conducting a two-sided hypothesis test, then both large positive values and large negative values of our test statistic would lead credence to the null over the alternative.
- As such, our test would reject for large values of \(|\mathrm{TS}|\)
If instead our alternative took the form \(\mu_1 < \mu_2\); i.e. that \(\delta = \mu_2 - \mu_1 > 0\), our test would reject for large positive values of \(\mathrm{TS}\).
If instead our alternative took the form \(\mu_1 > \mu_2\); i.e. that \(\delta = \mu_2 - \mu_1 < 0\), our test would reject for large negative values of \(\mathrm{TS}\).
Again, the key is to note that after reparameterizing the problem to be in terms of the difference \(\delta = \mu_2 - \mu_1\), the problem becomes a familiar one-parameter problem.
Worked-Out Example
Worked-Out Example 2
A renter wants to know which city is cheaper to live in: GauchoVille or Bruin City. Specifically, she would like to test the null hypothesis that the two cities have the same average monthly rent against the alternative that GauchoVille has a higher average monthly rent.
As such, she takes a representative sample of 32 houses from GauchoVille (which she calls Population 1) and 32 houses from Bruin City (which she calls Population 2), and records the following information about her samples (all values are reported in thousands of dollars):
\[\begin{array}{r|cc} & \text{Sample Average} & \text{Sample Standard Deviation} \\ \hline \textbf{GauchoVille} & 3.2 & 0.50 \\ \textbf{Bruin City} & 3.5 & 0.60 \end{array}\]
- Write down the null and alternative hypotheses, taking care to define any relevant parameter(s).
- Compute the value of the test statistic.
- Assuming the null is correct, what is the distribution of the test statistic? Be sure to include any/all relevant parameter(s)! (Assume all independence and normality conditions are met.)
- What is the critical value of the test, if we are to use a 5% level of significance?
- Conduct the relevant test at a 5% level of significance, and report your conclusions in the context of the problem.
Solutions
- Let \(\mu_1\) denote the true average monthly rent in Population 1 (GauchoVille) and let \(\mu_2\) denote the true average monthly rent in Population 2 (Bruin City). Then, the null and alternative hypotheses can be phrased as: \[ \left[ \begin{array}{rr} H_0: & \mu_1 = \mu_2 \\ H_A: & \mu_1 < \mu_2 \end{array} \right. \] which, phrased in terms of the difference \(\mu_2 - \mu_1\), is equivalent to \[ \left[ \begin{array}{rr} H_0: & \mu_2 - \mu_1 = 0 \\ H_A: & \mu_2 - \mu_1 > 0 \end{array} \right. \]
Solutions
- We compute
\[\begin{align*} \mathrm{TS} & = \frac{\overline{Y} - \overline{X}}{\sqrt{\frac{s_X^2}{n_1} + \frac{s_Y^2}{n_2}}} \\ & = \frac{3.5 - 3.2}{\sqrt{\frac{0.5^2}{32} + \frac{0.6^2}{32} }} \approx \boxed{2.173} \end{align*}\]
Solutions
- We know that, under the null, the test statistic (assuming all independence and normality conditions hold) follows a t-distribution with degrees of freedom given by the Satterthwaite Approximation. As such, we should first compute the degrees of freedom:
\[\begin{align*} \mathrm{df} & = \mathrm{round}\left\{ \frac{ \left[ \left( \frac{s_X^2}{n_1} \right) + \left( \frac{s_Y^2}{n_2} \right) \right]^2 }{ \frac{\left( \frac{s_X^2}{n_1} \right)^2}{n_1 - 1} + \frac{\left( \frac{s_Y^2}{n_2} \right)^2}{n_2 - 1} } \right\} \\ & = \mathrm{round}\left\{ \frac{ \left[ \left( \frac{0.5^2}{32} \right) + \left( \frac{0.6^2}{32} \right) \right]^2 }{ \frac{\left( \frac{0.5^2}{32} \right)^2}{32 - 1} + \frac{\left( \frac{0.6^2}{32} \right)^2}{32 - 1} } \right\} \\ & = \mathrm{round}\{60.04737\} = 60 \end{align*}\]
- Therefore, \(\mathrm{TS} \stackrel{H_0}{\sim} t_{60}\)
Solutions
Recall that we have an upper-tailed alternative. As such, the critical value will be the \((1 - 0.05) \times 100 = 95\)th percentile of the \(t_{60}\) distribution. From our table, we see that this is .
We reject when our test statistic is larger than the critical value (again, since we are using an upper-tailed alternative). Since \(\mathrm{TS} = 2.173 > 1.67\), we reject the null:
At a 5% level of significance, there was sufficient evidence to reject the null that the average monthly rent in the two cities is the same against the alternative that the average monthly rent in Bruin City is higher than that in GauchoVille.
- Quick aside: do you think it was a valid assumption to make that the “normality conditions” hold?
Analysis of Variance
Multiple Populations
Suppose, instead of comparing two population means, we compare k population means \(\mu_1, \cdots, \mu_k\).
This is one framework in which ANOVA (Analysis of Variance) is useful.
Given \(k\) populations, each assumed to be normally distributed, with means \(\mu_1, \cdots, \mu_k\), ANOVA tests the following hypotheses: \[ \left[ \begin{array}{rl} H_0: & \mu_1 = \mu_2 = \cdots = \mu_k \\ H_A: & \text{at least one of the $\mu_i$'s is different from the others} \end{array} \right. \]
ANOVA
Specifically, ANOVA utilizes the so-called F-statistic \[ \mathrm{F} = \frac{\mathrm{MS}_{\mathrm{G}}}{\mathrm{MS}_{E}} \] where \(\mathrm{MS}_{\mathrm{G}}\), the mean square between groups, can be thought of as a measure of variability between group means, and \(\mathrm{MS}_{\mathrm{E}}\), the mean squared error, can be thought of as a measure of variability within groups/variability due to chance.
If \(\mathrm{MS}_{\mathrm{G}}\) is much larger than \(\mathrm{MS}_{\mathrm{E}}\) - i.e. if the variability between groups is much more than what we would expect due to chance alone - we would likely reject the null that all group means were the same.
- As such, ANOVA rejects for values of the F-statistic that are large (i.e. much greater than 1).
ANOVA
Assuming the \(k\) populations follow independent normal distributions, the F-statistic follows an F-distribution under the null.
- Specifically, \(F \sim F_{k-1, \ n - k}\) where \(n\) is the total number of observations across all groups.
Since we reject \(H_0\) (in favor of \(H_A\)) whenever \(F\) is large, we always compute p-values in ANOVA using right-tail probabilities:
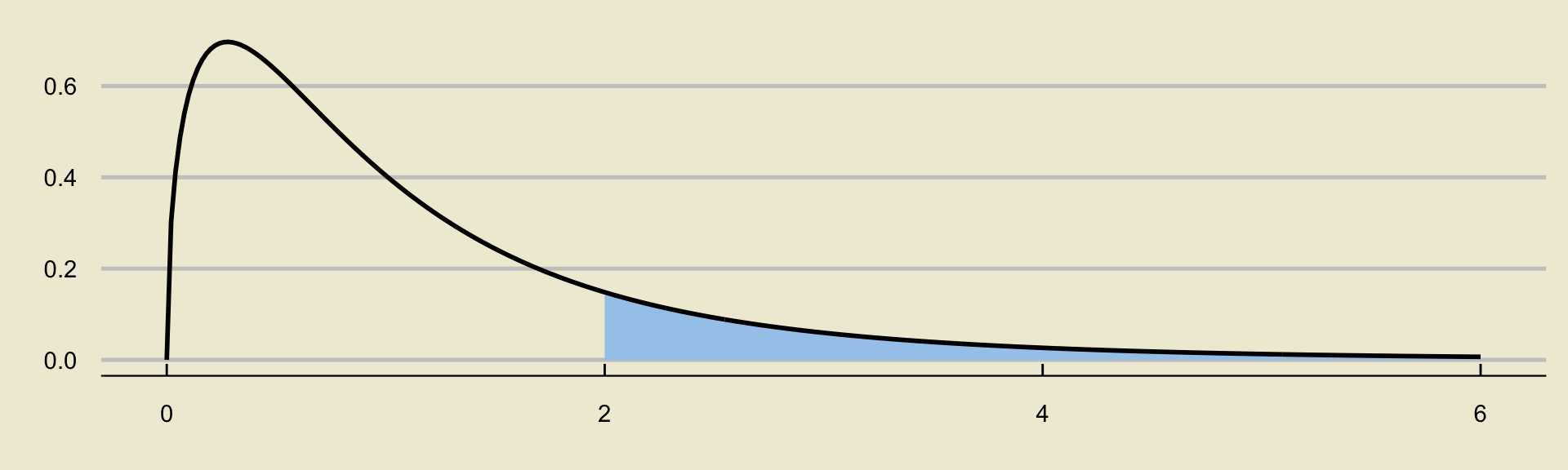
ANOVA
- The results of an ANOVA are typically displayed by way of an ANOVA Table:
| DF | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| Between Groups | \(k - 1\) | \(\mathrm{SS}_{\mathrm{G}}\) | \(\mathrm{MS}_{\mathrm{G}}\) | F | p-value |
| Residuals | \(n - k\) | \(\mathrm{SS}_{\mathrm{E}}\) | \(\mathrm{MS}_{\mathrm{E}}\) |
- You should familiarize yourself with how these quantities relate to each other; specifically, that \[ \mathrm{MS}_{\mathrm{G}} = \frac{\mathrm{SS}_{\mathrm{G}}}{k - 1} ; \quad \mathrm{MS}_{\mathrm{E}} = \frac{\mathrm{SS}_{\mathrm{E}}}{n - k}; \quad F = \frac{\mathrm{MS}_{\mathrm{G}}}{\mathrm{MS}_{\mathrm{E}}} \]
