PSTAT 5A: Lecture 21
Regression, Part II
2023-07-31
OLS Estimators and the OLS Regression Line
Back to the model fitting problem: we seek to find “good” estimators \(\widehat{\beta}_0\) and \(\widehat{\beta}_1\) for \(\beta_0\) and \(\beta_1\) respectively.
One quantification of “good” is “minimizing the residual sum of squares”:
 \[ \mathrm{RSS} = \sum_{i=1}^{n} e_i^2 \]
\[ \mathrm{RSS} = \sum_{i=1}^{n} e_i^2 \]
Fitted Values
- We also introduced the notion of fitted values:

- This is why we write the OLS regression line as \[ \widehat{y} = \widehat{\beta}_0 + \widehat{\beta}_1 \cdot x \] the fitted values are simply the points along the OLS regression line!
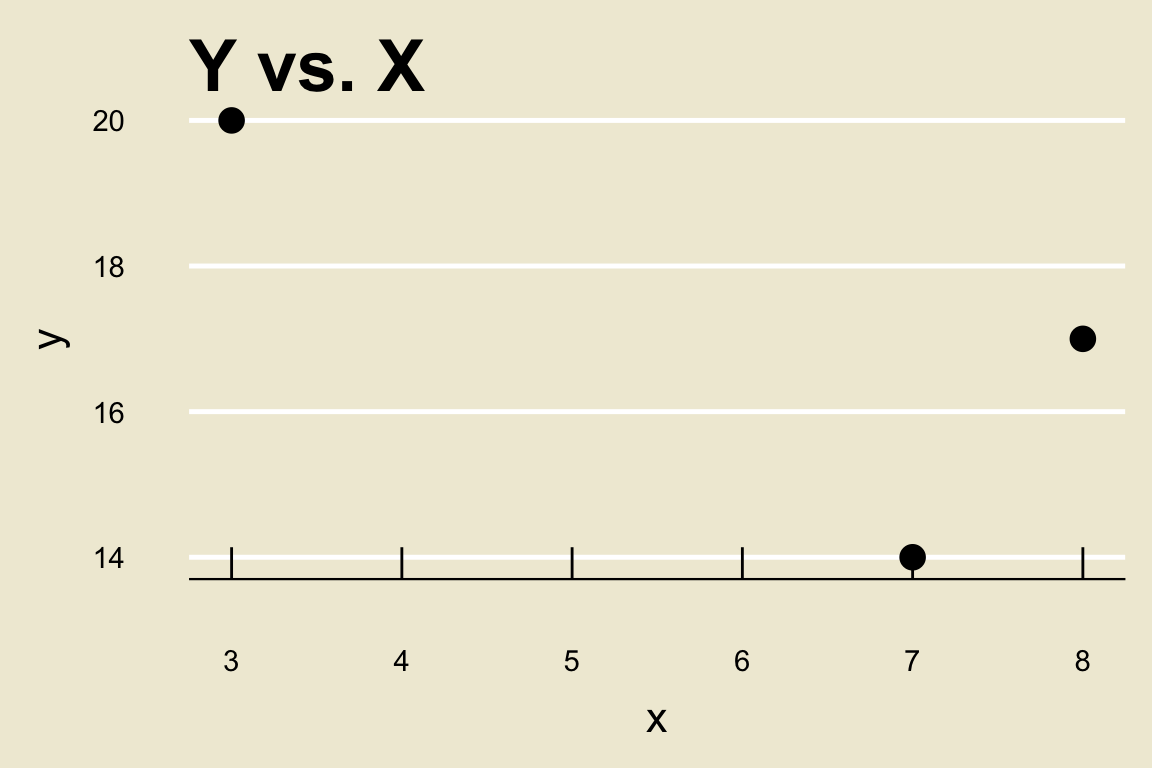
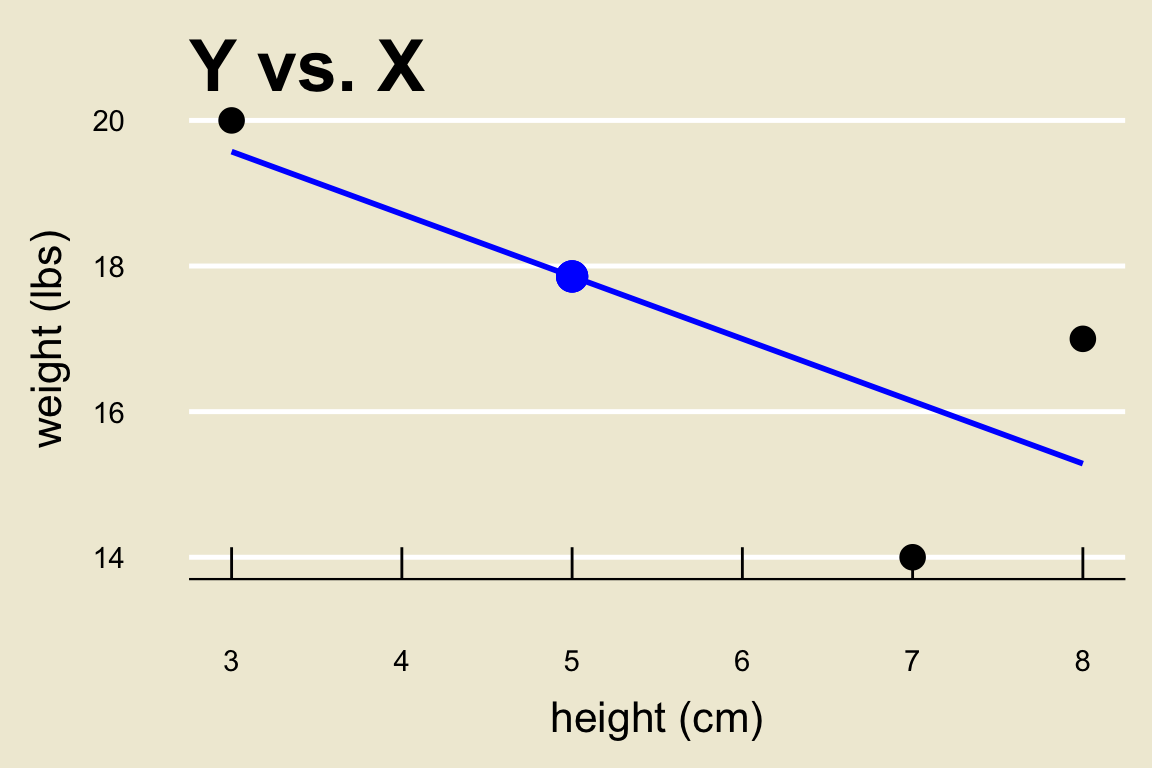
Prediction
Notice that we do not have an
x-observation of 5. As such, we don’t know what they-value corresponding to anx-value of 5 is.However, we do have a decent guess as to what the
y-value corresponding to anx-value of 5 is- the corresponding fitted value!
Leadup
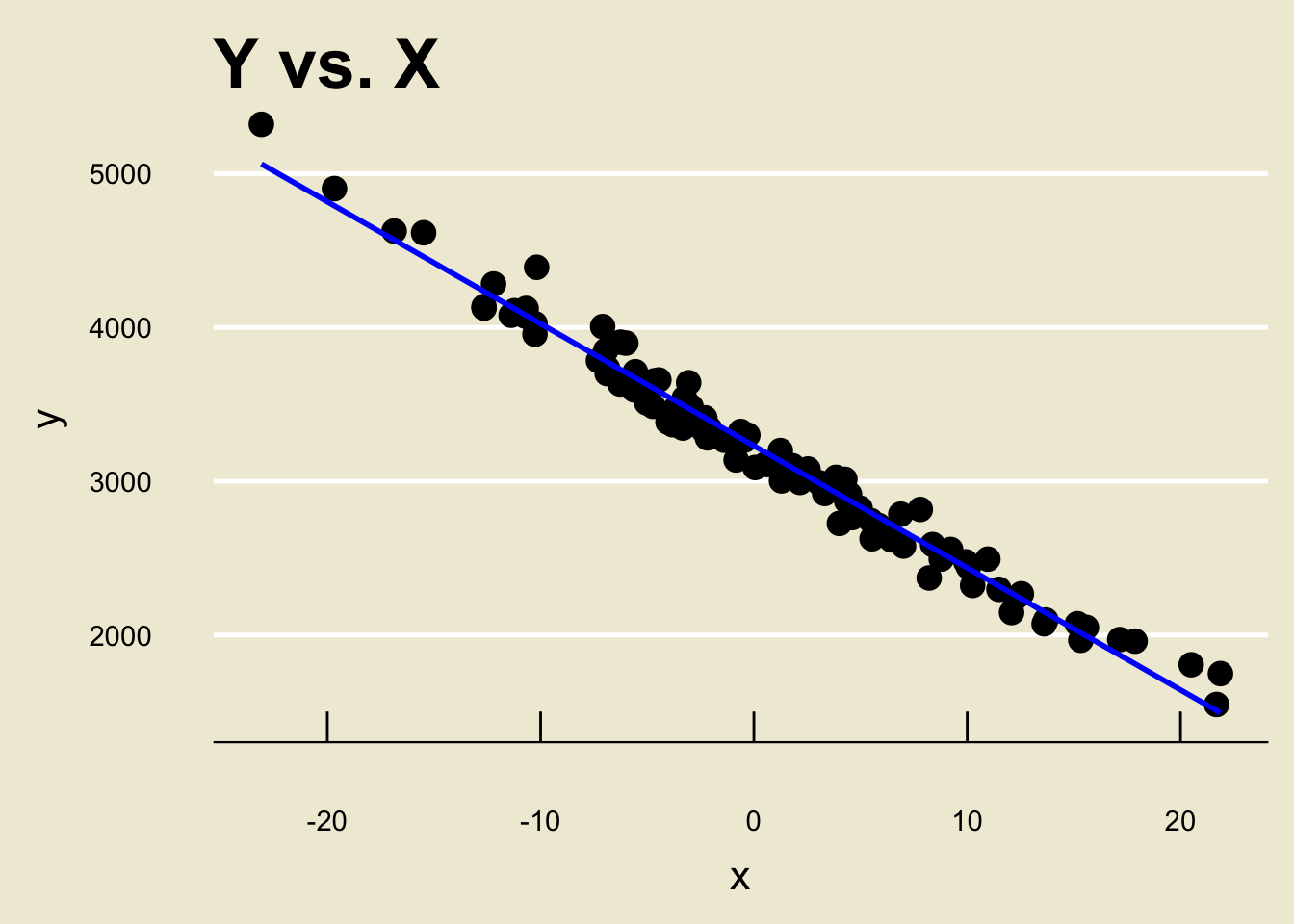
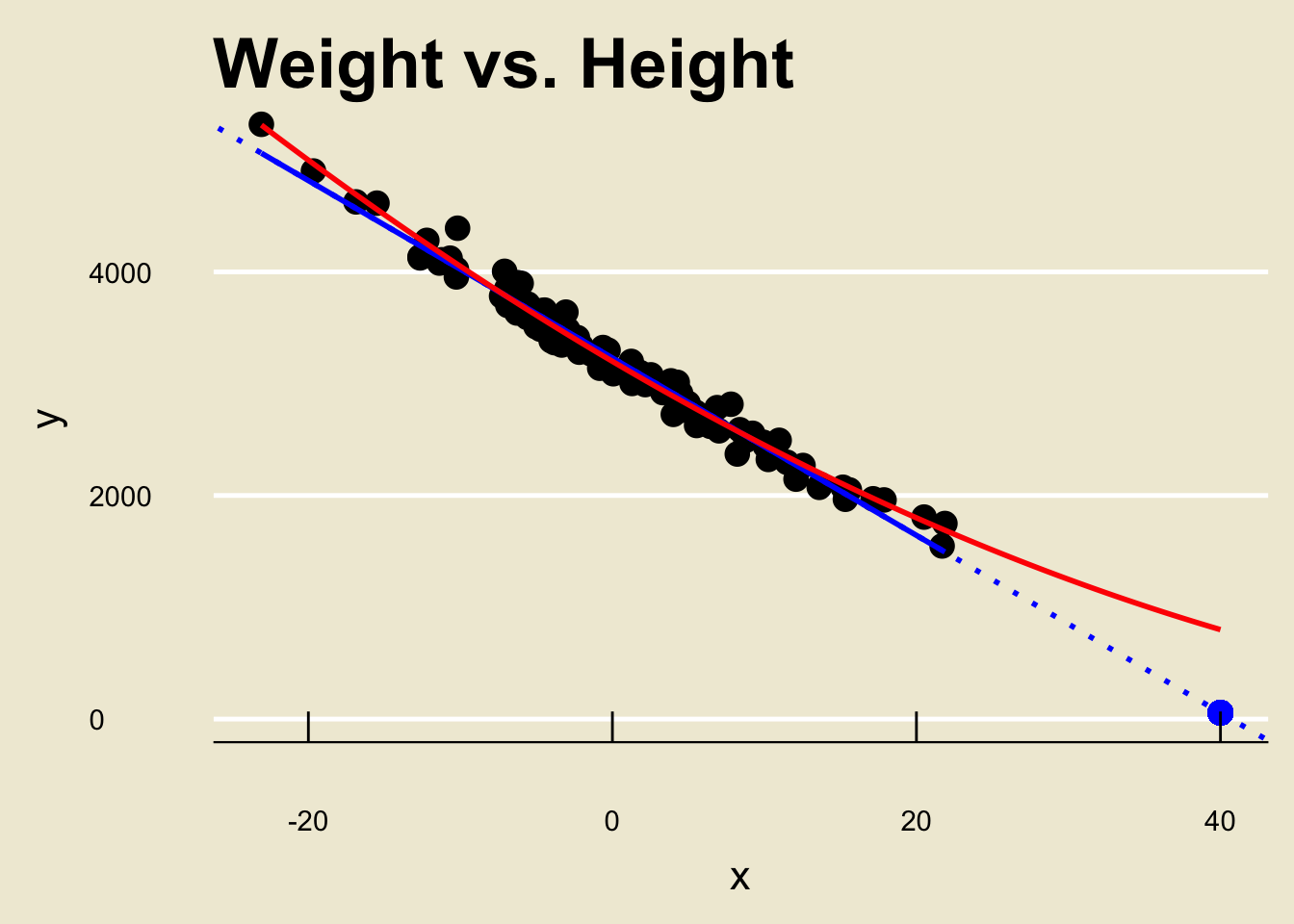
- Let’s look at another toy dataset:
Leadup
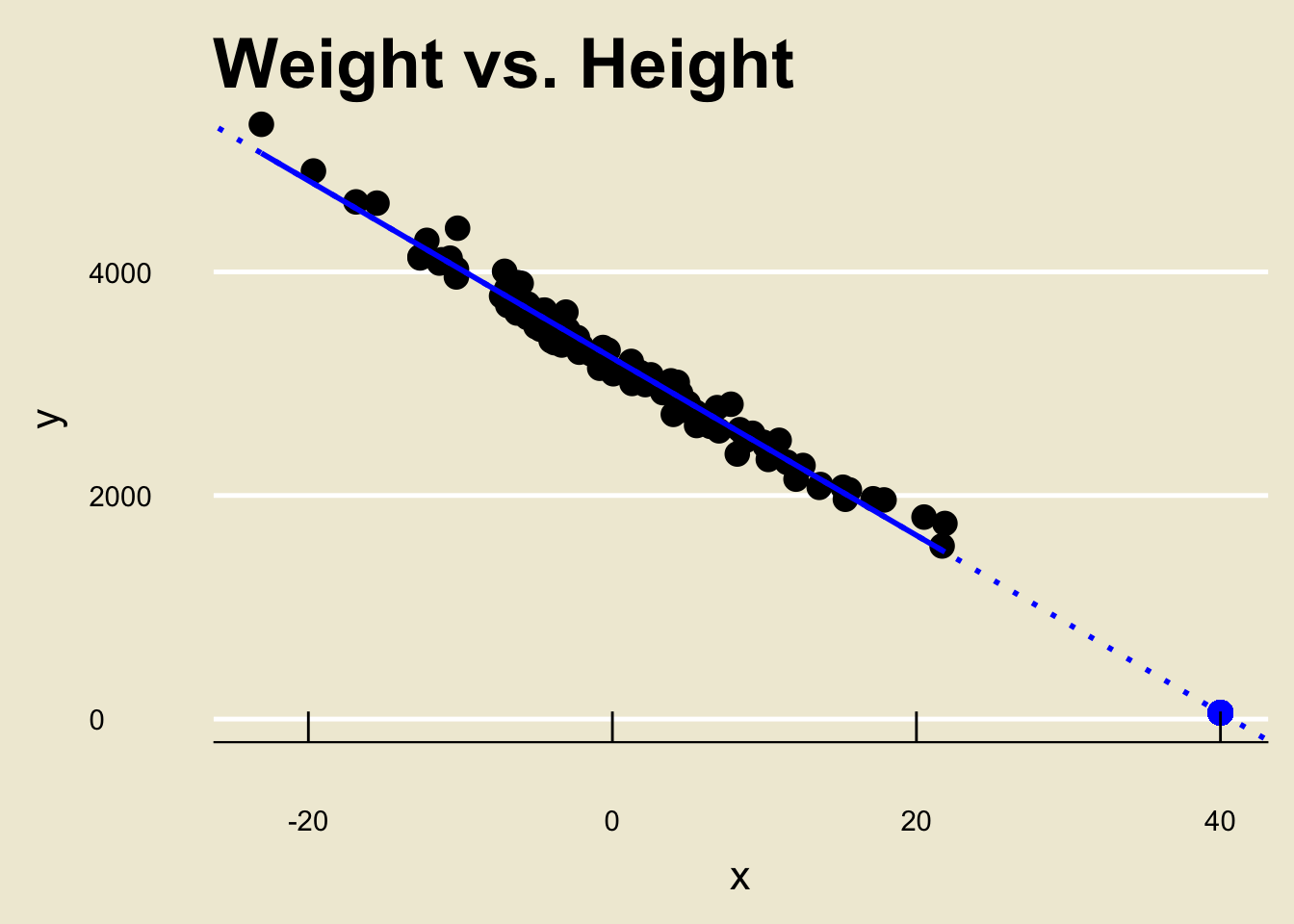
Say we want to predict the corresponding
yvalue of anxvalue of, 40.Following our steps from before, we would just find the fitted value corresponding to
x= 40:
Leadup
- Here’s the kicker: the true fit was actually NOT linear!
Example
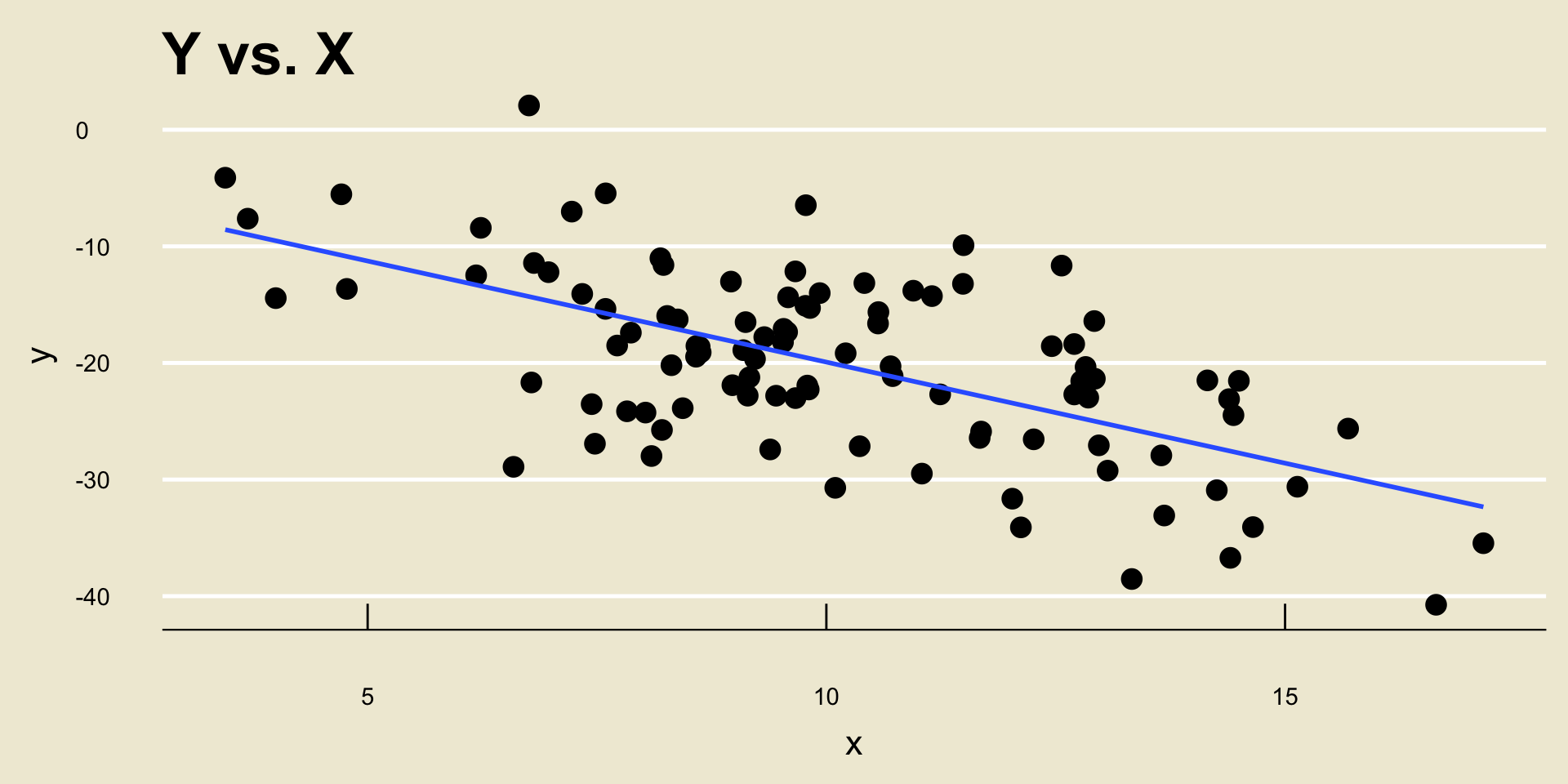
- \(\widehat{\beta_0} =\) -2.5884231; \(\widehat{\beta_1} =\) -1.733778
Example
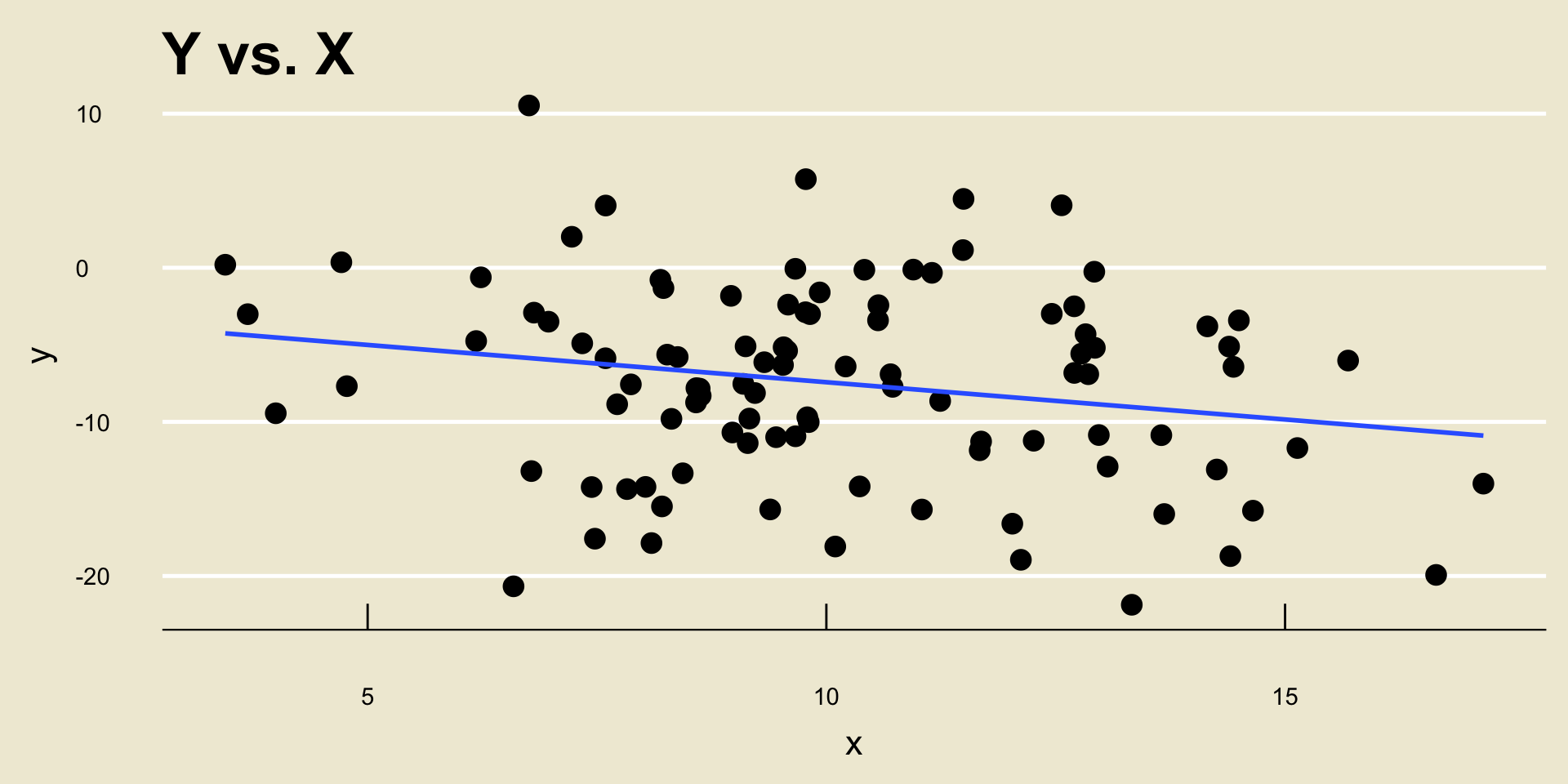
- \(\widehat{\beta_0} =\) -2.5884231; \(\widehat{\beta_1} =\) -0.483778
Example
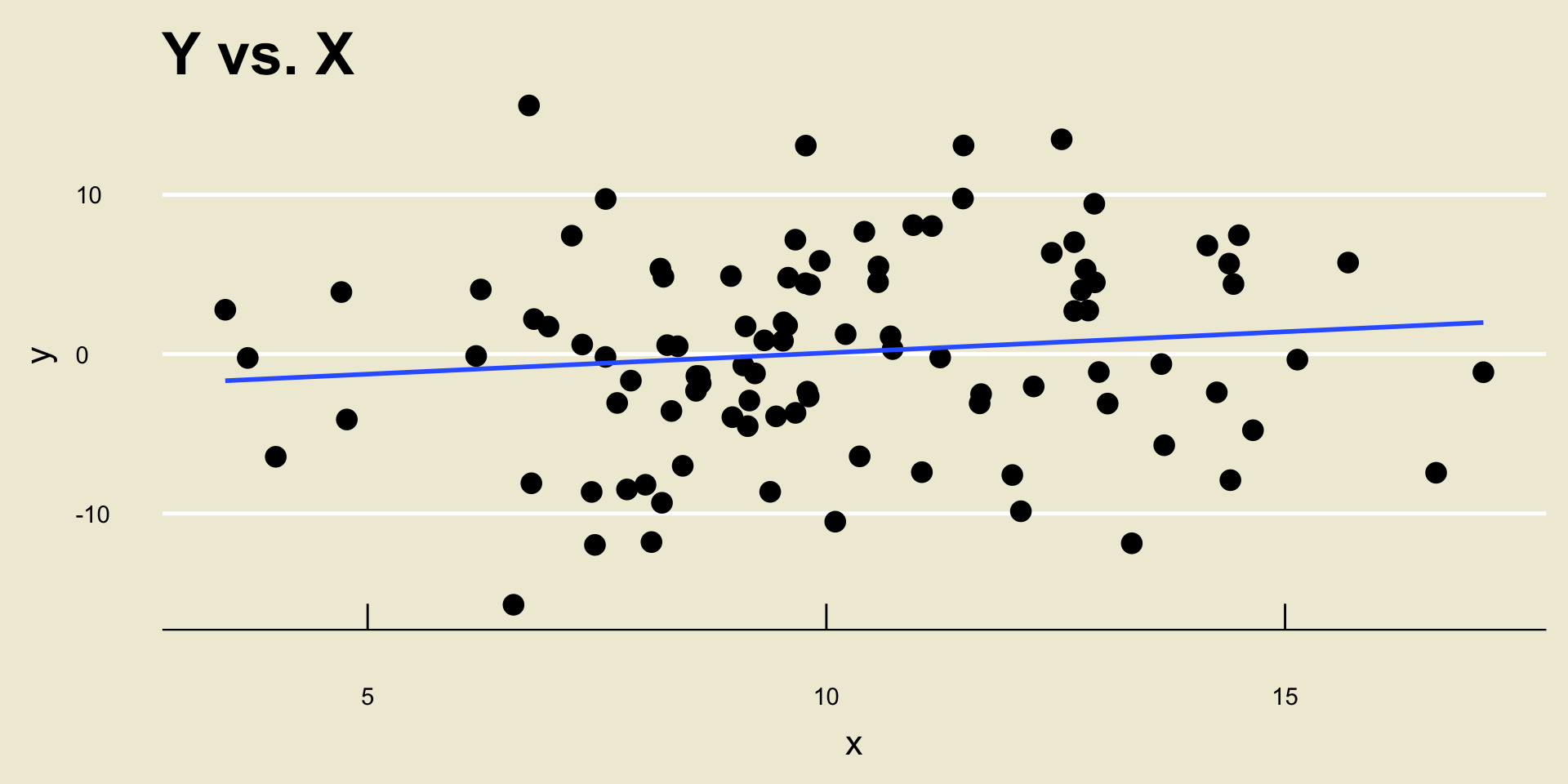
\(\widehat{\beta_0} =\) -2.5884231; \(\widehat{\beta_1} =\) 0.266222
Do we really believe the slope, though?
Some Exercises
Exercise 3 (modified from StatClass)
Ten towns were the subject of a study to determine whether or not an increased number of stores selling liquor in their downtown areas is linked with a higher number of DUI arrests downtown during one month. The data and summary information is provided below.
x |
0 | 5 | 6 | 5 | 11 | 9 | 10 | 3 | 7 | 4 |
|---|---|---|---|---|---|---|---|---|---|---|
y |
40 | 50 | 55 | 64 | 73 | 75 | 88 | 25 | 20 | 10 |
\[ \begin{array}{lll} \overline{x} = 6 & \displaystyle \sum_{i=1}^{10} (x_i - \overline{x})^2 = 102 \\ \overline{y} = 50 & \displaystyle \sum_{i=1}^{10} (y_i - \overline{y})^2 = 6,\!024 & \displaystyle \sum_{i=1}^{10} (x_i - \overline{x})(y_i - \overline{y}) = 513 \end{array} \]
- What is the explanatory variable?
- What is the response variable?
- Find the equation of the OLS regression line.
- If the standard deviation of \(\widehat{\beta}_1\) is \(0.37\), construct a 95% confidence interval for \(\beta_1\).
- Is the slope significant? (Use the standard deviation from part (d) if necessary.)
