species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
7 Adelie Torgersen 38.9 17.8 181 3625
8 Adelie Torgersen 39.2 19.6 195 4675
9 Adelie Torgersen 34.1 18.1 193 3475
10 Adelie Torgersen 42 20.2 190 4250
# ℹ 334 more rows
# ℹ 2 more variables: sex <fct>, year <int>PSTAT 5A: Midterm 1 Review
Overview of Weeks 1 and 2
2023-07-05
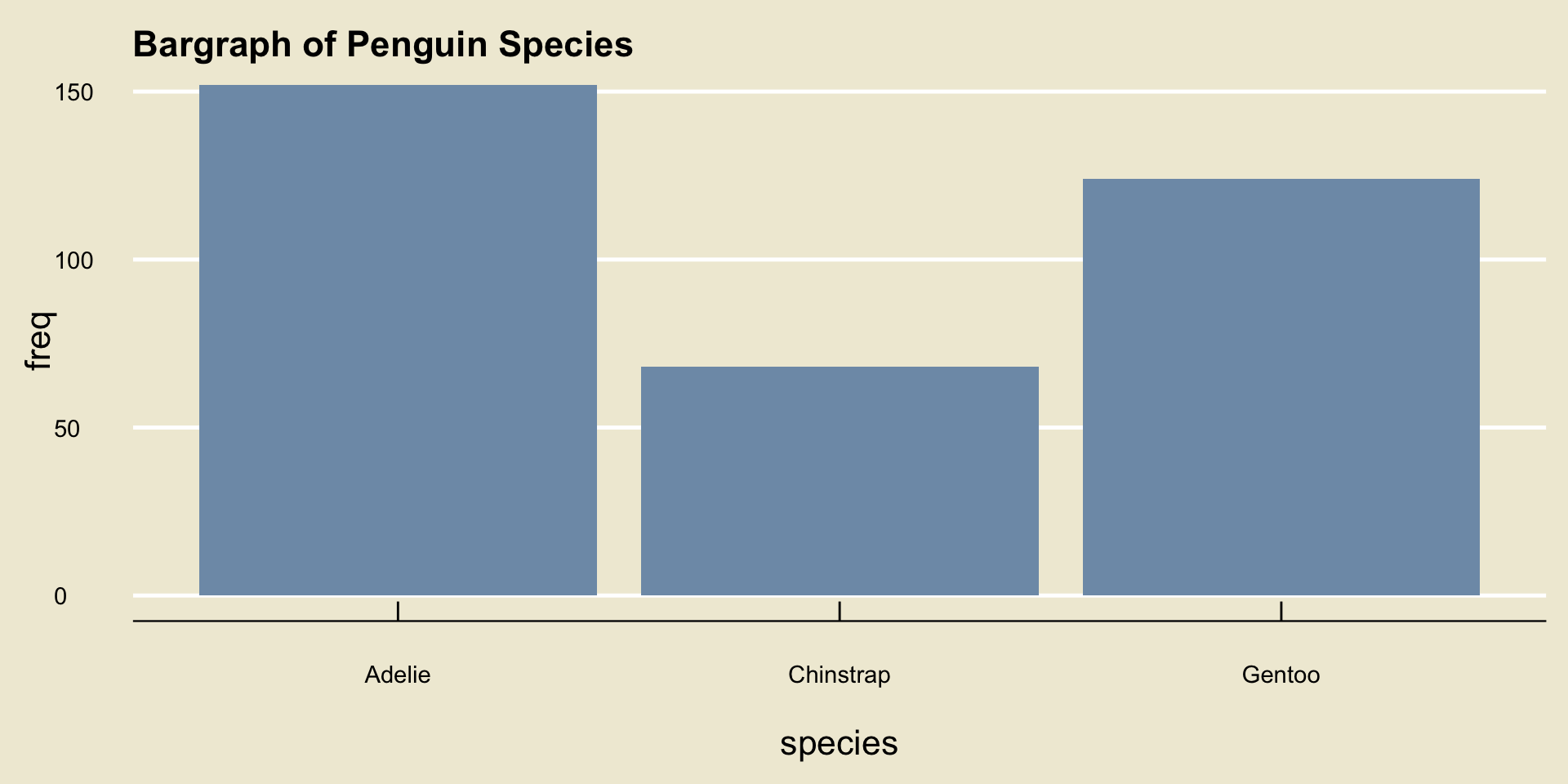
Bargraph
Histogram
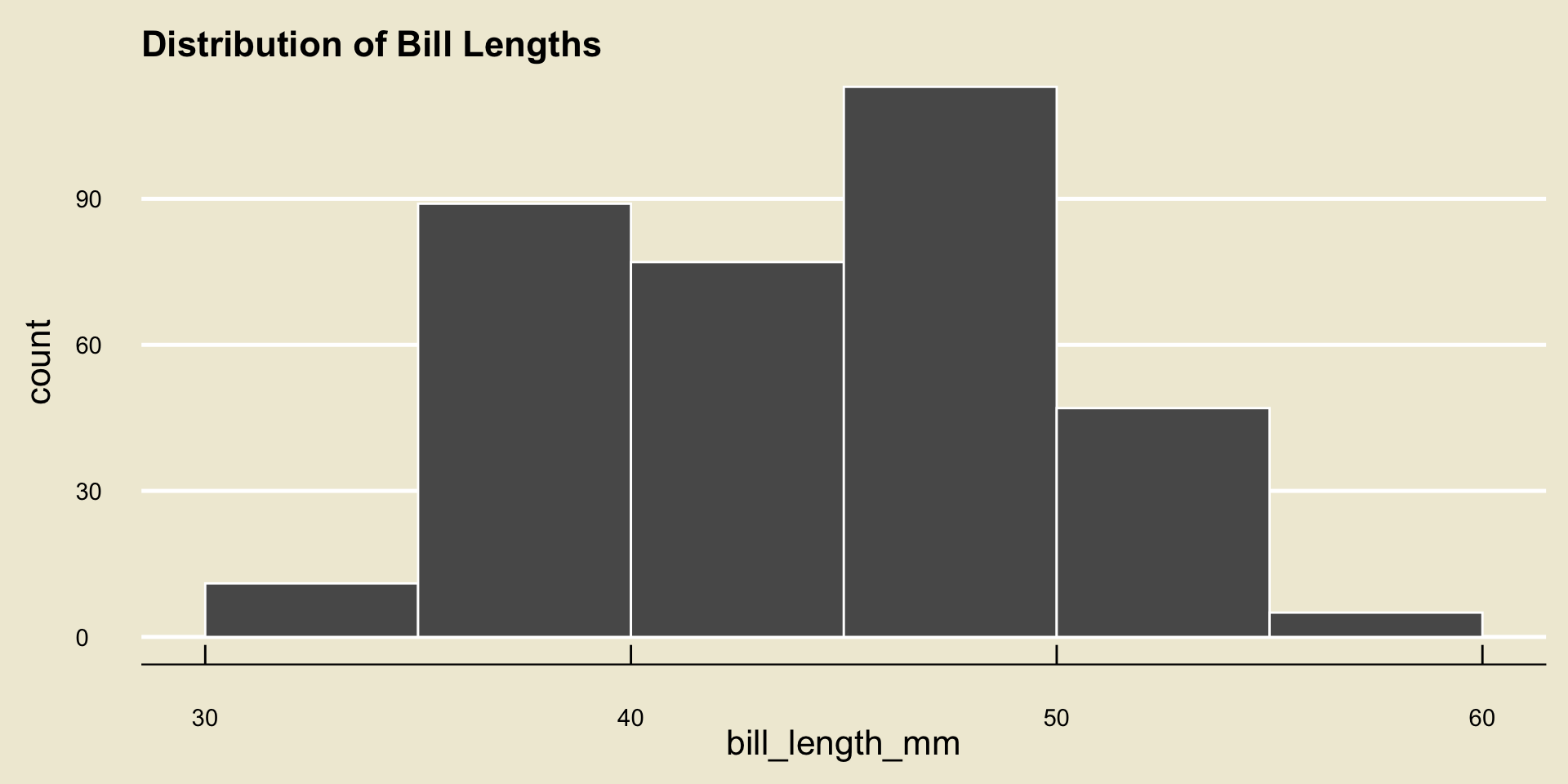
- Remember the importance of binwidth: demo
Boxplot
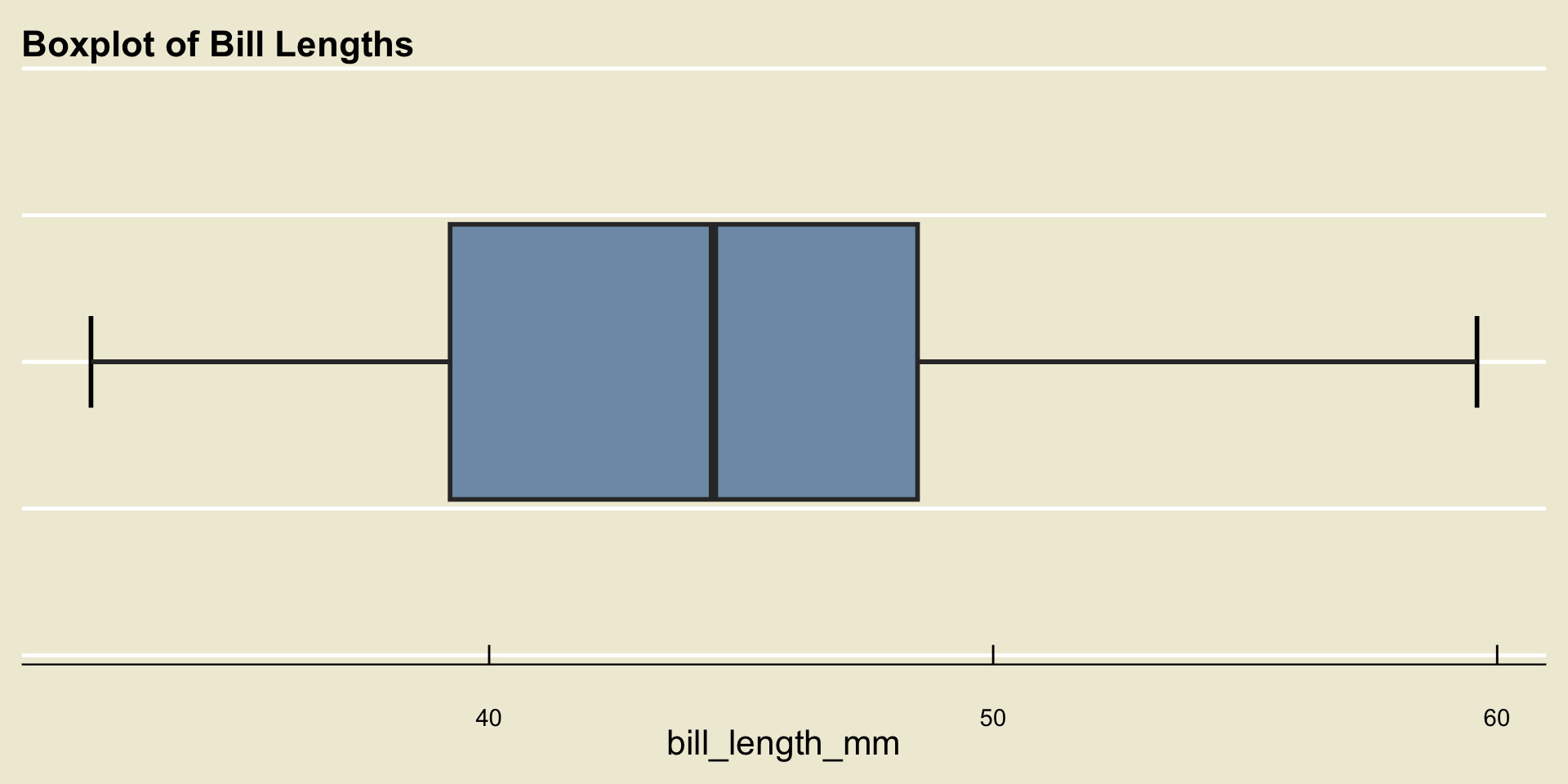
- Remember that the whiskers are never allowed to extend beyond 1.5 times the IQR (and recall that the IQR is just the width of the box).
The Mean
- The mean (or arithmetic mean) is a sort of “balancing point”:

\[ \overline{x} = \frac{1}{n} \sum_{i=1}^{n} x_i \]
- Also recall our discussion on data aggregation, and how the incorporation of new data changes the mean.
Spread
Another way we could summarize a numerical dataset (i.e. a dataset containing only one variable, one that is numerical) is to describe how “spread out” the values are.
The variance is a sort of “average distance of points to the mean”:

\[ s_x^2 = \frac{1}{n - 1} \sum_{i=1}^{n} (x_i - \overline{x})^2 \]
- The standard deviation is just the square root of the variance
- Linear Negative Trend:
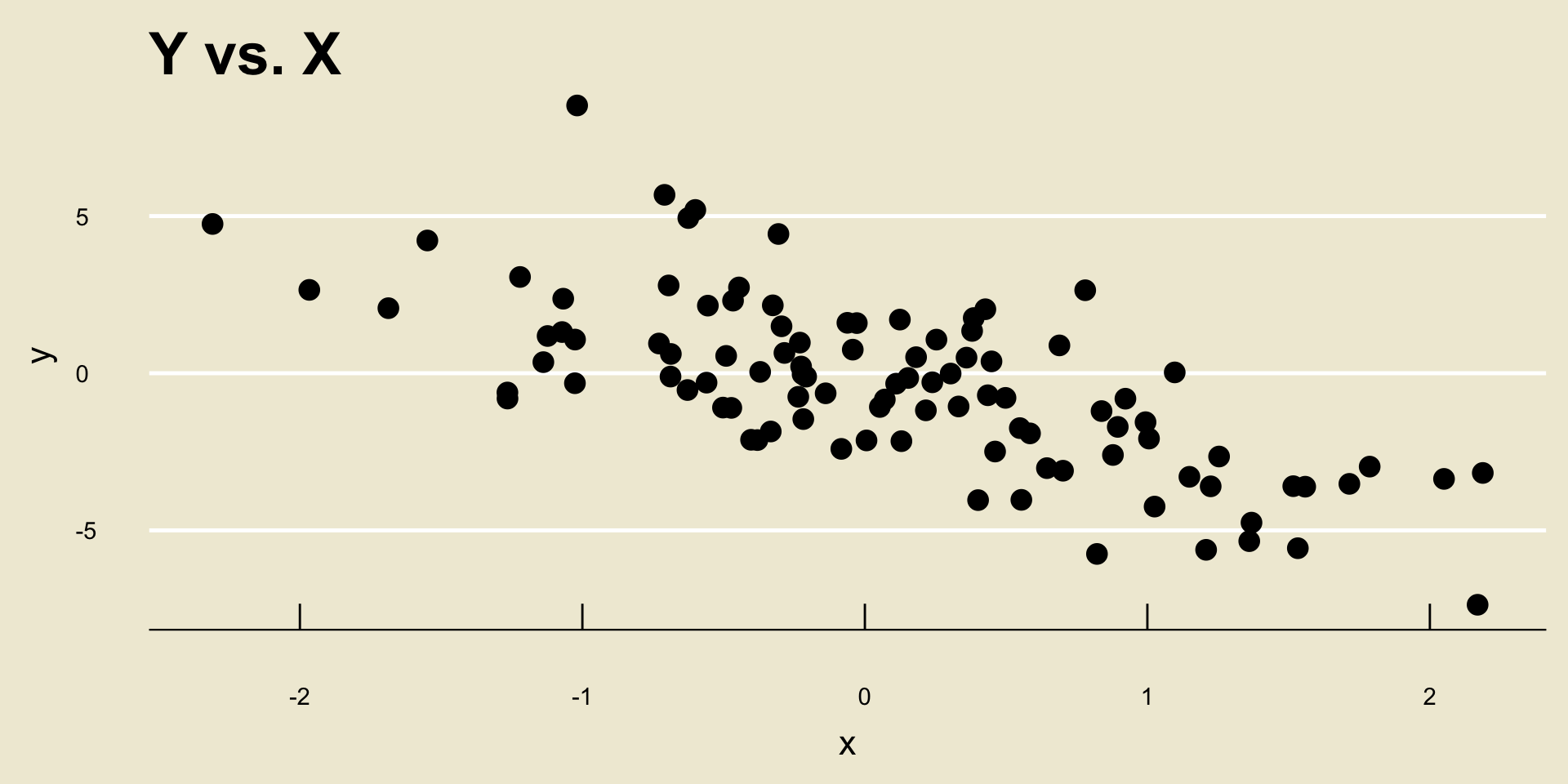
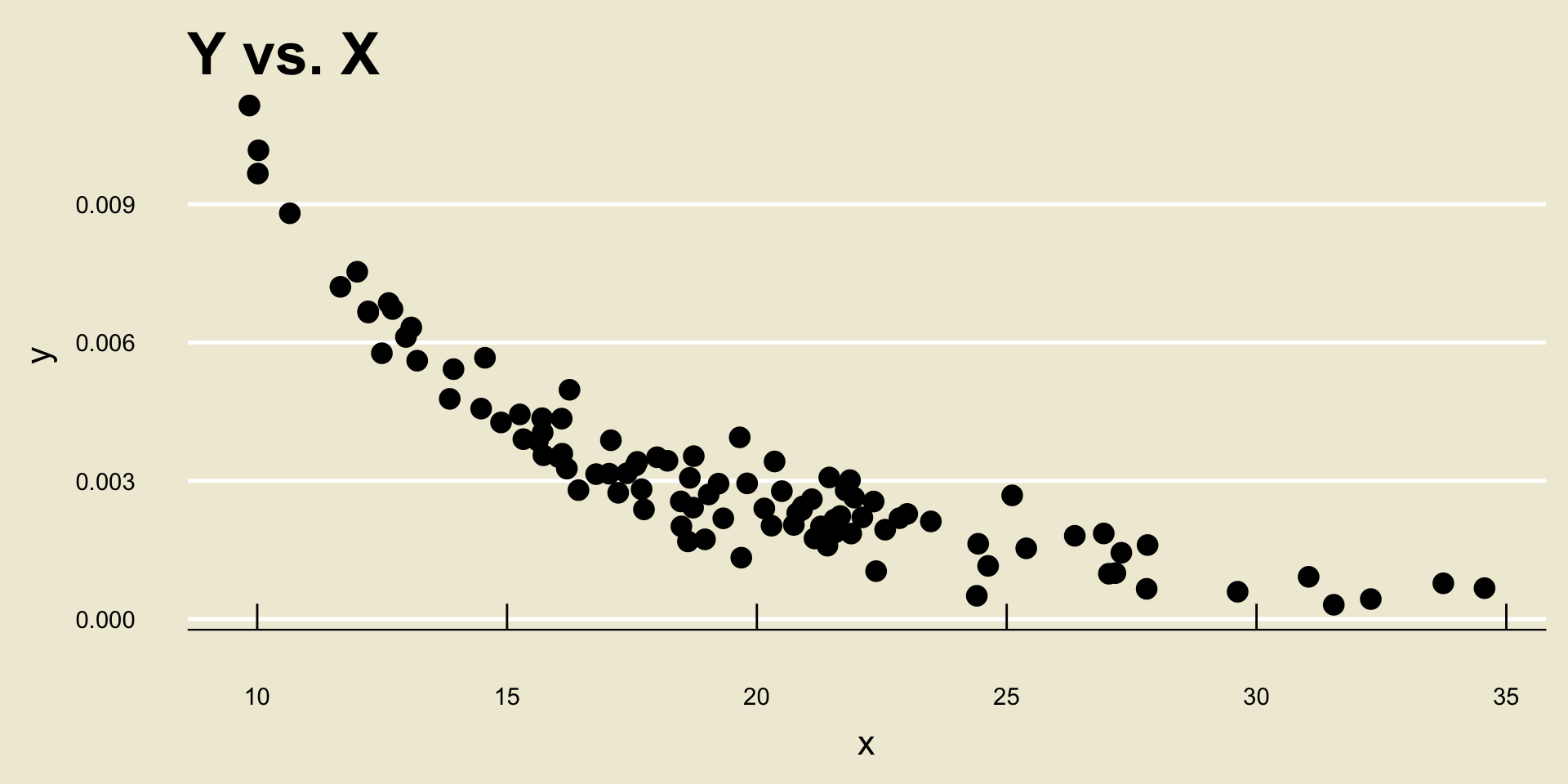
- Nonlinear Negative Trend:
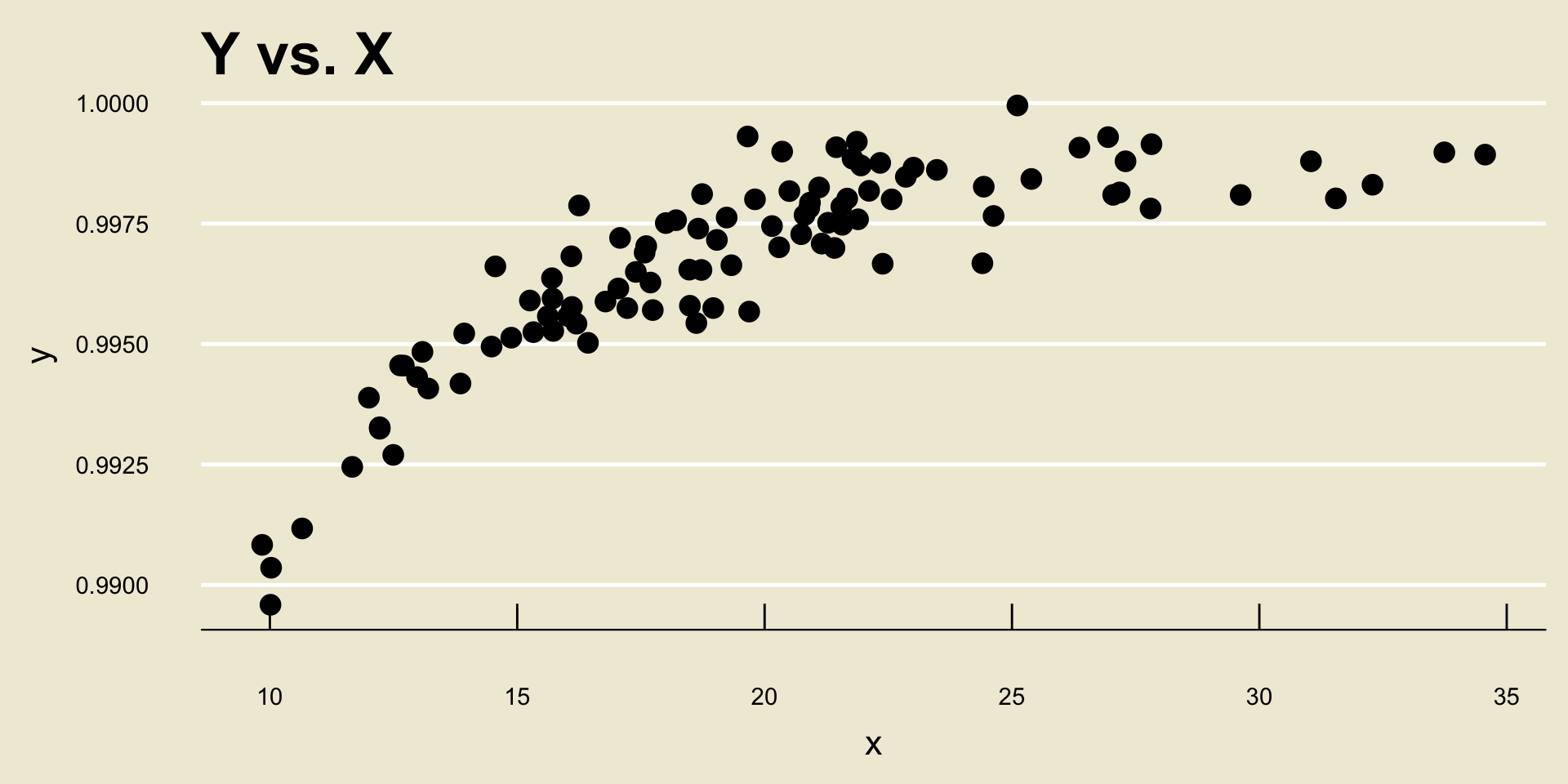
- Nonlinear Positive Trend:
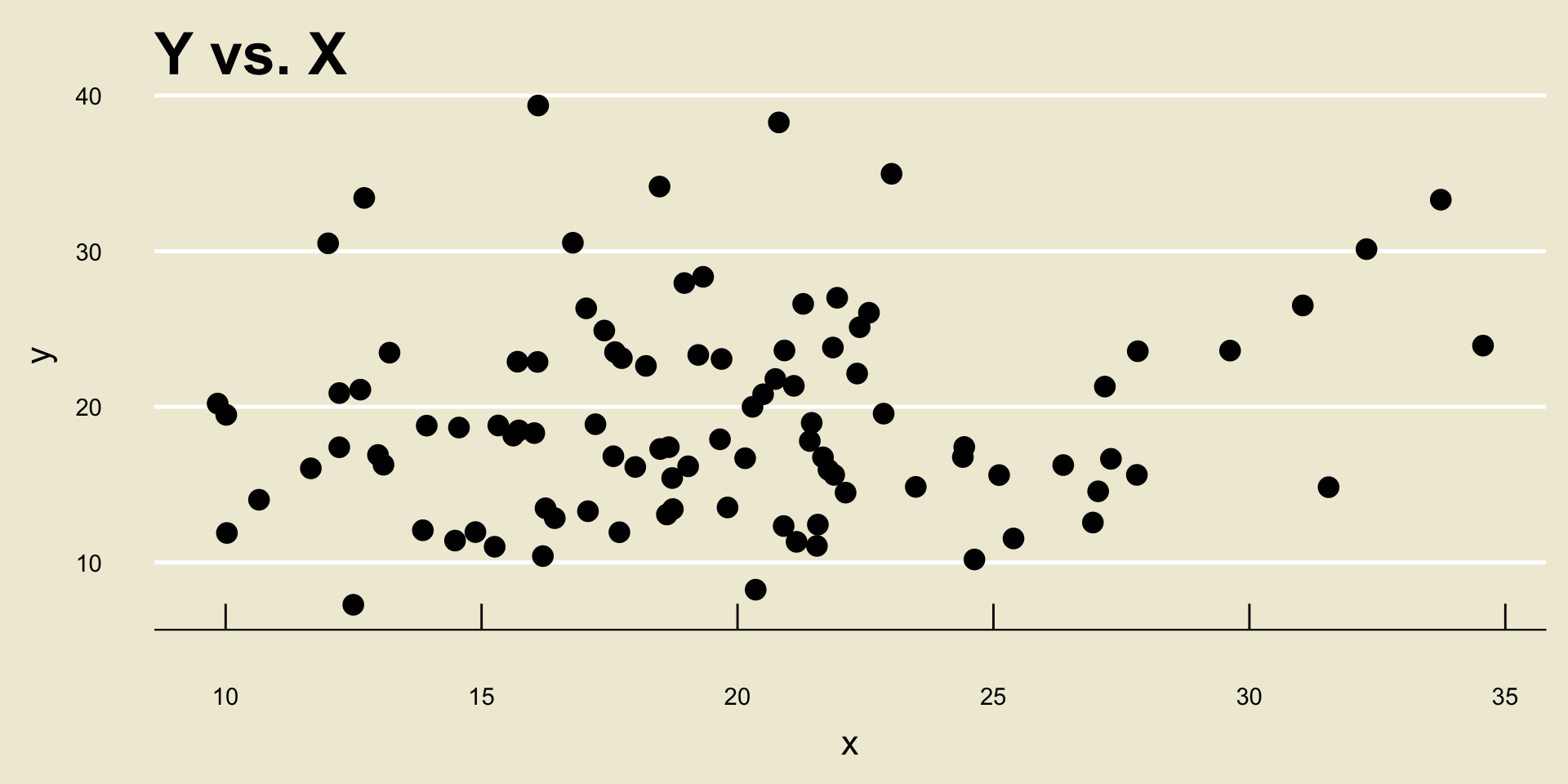
- No Discernable Trend
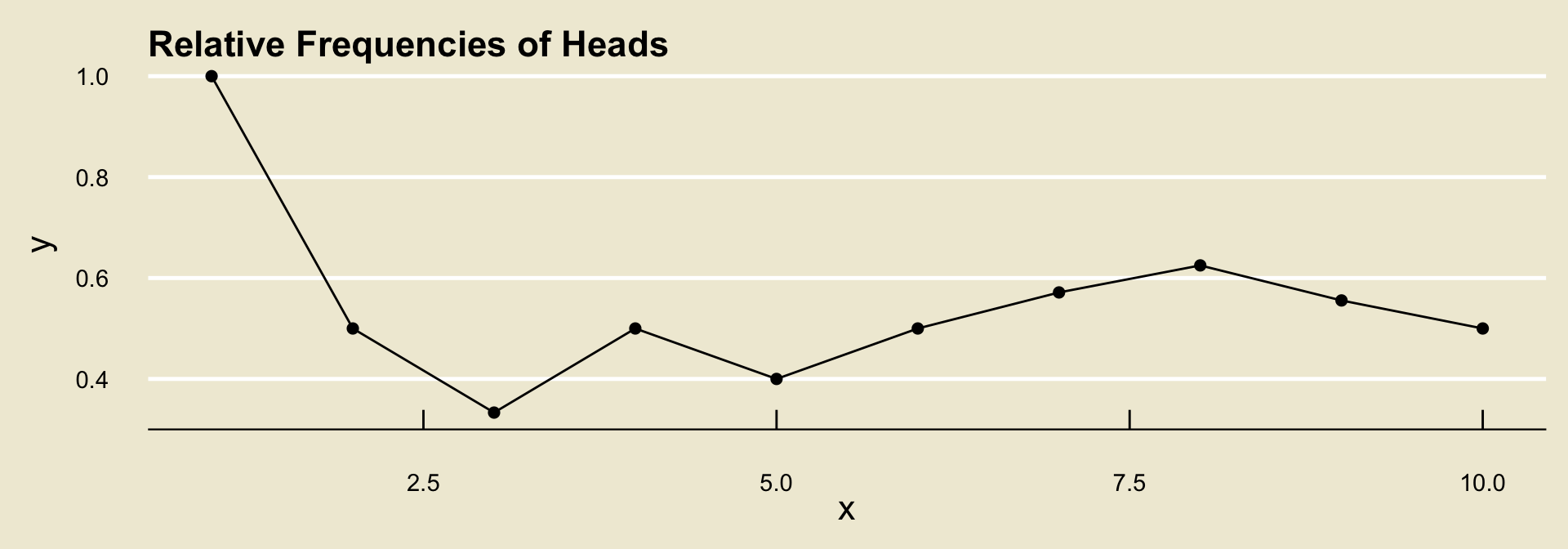
Long-Run Frequencies Example
| Toss | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Outcome | H |
T |
T |
H |
T |
H |
H |
H |
T |
T |
Raw freq. of H |
1 | 1 | 1 | 2 | 2 | 3 | 4 | 5 | 5 | 5 |
Rel. freq of H |
1/1 | 1/2 | 1/3 | 2/4 | 2/5 | 3/6 | 4/7 | 5/8 | 5/9 | 5/10 |
Venn Diagrams

\(A^\complement\)
(complement)

\(A \cap B\)
(intersection)

\(A \cup B\)
(union)
Exercise
Exercise
Write a function is_mult_of_three() that takes in a single input x and outputs True if x is a multiple of three and False if not. Additionally, the function should return "Error: input must be numeric" if the argument x that is provided is not numerical.
- Take a moment to open up our JupyterHub server instance, and try writing out the function on your own. Then we’ll work through it together (please note that solutions to this won’t be provided, so make sure you take notes!)
